OSI和TCP/IP在封装过程中如何实现实时性OSI和TCP/IP在封装过程中如何实现实时性
在了解封装和解封装之前,你必须要知道什么是协议数据单元(PDU)!
在OSI七层模型或者TCP/IP协议
大数据流式计算Spark Steaming、Storm、Scribe那个更好用?
电脑
2022-06-30
hadoop,storm和spark的区别,比较
一、hadoop、Storm该选哪一个? 为了区别hadoop和Storm,该部分将回答如下问题: 1.hadoop、Storm各是什么运算 2.Storm为什么被称之为流式计算系统 3.hadoop适合什么场景,什么情况下使用hadoop 4.什么是吞吐量 首先整体认识:Hadoop是磁盘级计算,进行计算时,数据在磁盘上,需要读写磁盘;Storm是内存级计算,数据直接通过网络导入内存。读写内存比读写磁盘速度快n个数量级。根据Harvard CS61课件,磁盘访问延迟约为内存访问延迟的75000倍。所以Storm更快。 注释: 1. 延时 , 指数据从产生到运算产生结果的时间,“快”应该主要指大数据好不好学
大数据目前发展是比较好的,特别是在鸿蒙发布后物联网时代的到来下,大数据相关岗位将会更多。想要转行的话,大数据的确是个很好的方向。既然想要转行大数据,那么肯定要具备大数据的相关知识与技能,系统学习的话是不难学的。
这里介绍一下大数据要学习和掌握的知识与技能:
①java:一门面向对象的计算机编程语言,具有功能强大和简单易用两个特征。
②spark:专为大规模数据处理而设计的快速通用的计算引擎。
③SSM:常作为数据源较简单的web项目的框架。
④Hadoop:分布式计算和存储的框架,需要有java语言基础。
⑤spring cloud:一系列框架的有序集合,他巧妙地简化了分布式系统基础设施的开发。
⑤python:一个高层次的结合了解释性、编译性、互动性和面向对象的脚本语言。
大数据可以从事的职业:
①大数据维护、研发、架构工程师方向
所涉及的专业岗位为:大数据工程师、大数据维护工程师、大数据研发工程师、大数据架构师等;
②大数据挖掘、分析方向
所涉及的专业岗位为:大数据分析师、大数据高级工程师、大数据分析师专家、大数据挖掘师、大数据算法师等;
互联网行业目前还是最热门的行业之一,学习IT技能之后足够优秀是有机会进入腾讯、阿里、网易等互联网大厂高薪就业的,发展前景非常好,普通人也可以学习。
想要系统学习,你可以考察对比一下开设有相关专业的热门学校,好的学校拥有根据当下企业需求自主研发课程的能力,能够在校期间取得大专或本科学历,中博软件学院、南京课工场、南京北大青鸟等开设相关专业的学校都是不错的,建议实地考察对比一下。
祝你学有所成,望采纳。

大数据方面核心技术有哪些?
简单来说,从大数据的生命周期来看,无外乎四个方面:大数据采集、大数据预处理、大数据存储、大数据分析,共同组成了大数据生命周期里最核心的技术,下面分开来说:
大数据采集
数据库采集:流行的有Sqoop和ETL,传统的关系型数据库MySQL和Oracle 也依然充当着许多企业的数据存储方式。当然了,目前对于开源的Kettle和Talend本身,也集成了大数据集成内容,可实现hdfs,hbase和主流Nosq数据库之间的数据同步和集成。
网络数据采集:一种借助网络爬虫或网站公开API,从网页获取非结构化或半结构化数据,并将其统一结构化为本地数据的数据采集方式。
文件采集:包括实时文件采集和处理技术flume、基于ELK的日志采集和增量采集等等。
大数据预处理
数据清理:指利用ETL等清洗工具,对有遗漏数据(缺少感兴趣的属性)、噪音数据(数据中存在着错误、或偏离期望值的数据)、不一致数据进行处理。
数据集成:是指将不同数据源中的数据,合并存放到统一数据库的,存储方法,着重解决三个问题:模式匹配、数据冗余、数据值冲突检测与处理。
数据转换:是指对所抽取出来的数据中存在的不一致,进行处理的过程。它同时包含了数据清洗的工作,即根据业务规则对异常数据进行清洗,以保证后续分析结果准确性。
数据规约:是指在最大限度保持数据原貌的基础上,最大限度精简数据量,以得到较小数据集的操作,包括:数据方聚集、维规约、数据压缩、数值规约、概念分层等。
大数据存储,指用存储器,以数据库的形式,存储采集到的数据的过程,包含三种典型路线:
大数据采集,即对各种来源的结构化和非结构化海量数据,所进行的采集。
大数据预处理,指的是在进行数据分析之前,先对采集到的原始数据所进行的诸如“清洗、填补、平滑、合并、规格化、一致性检验”等一系列操作,旨在提高数据质量,为后期分析工作奠定基础。数据预处理主要包括四个部分:数据清理、数据集成、数据转换、数据规约。
1、基于MPP架构的新型数据库集群
采用Shared Nothing架构,结合MPP架构的高效分布式计算模式,通过列存储、粗粒度索引等多项大数据处理技术,重点面向行业大数据所展开的数据存储方式。具有低成本、高性能、高扩展性等特点,在企业分析类应用领域有着广泛的应用。
较之传统数据库,其基于MPP产品的PB级数据分析能力,有着显著的优越性。自然,MPP数据库,也成为了企业新一代数据仓库的最佳选择。
2、基于Hadoop的技术扩展和封装
基于Hadoop的技术扩展和封装,是针对传统关系型数据库难以处理的数据和场景(针对非结构化数据的存储和计算等),利用Hadoop开源优势及相关特性(善于处理非结构、半结构化数据、复杂的ETL流程、复杂的数据挖掘和计算模型等),衍生出相关大数据技术的过程。
伴随着技术进步,其应用场景也将逐步扩大,目前最为典型的应用场景:通过扩展和封装 Hadoop来实现对互联网大数据存储、分析的支撑,其中涉及了几十种NoSQL技术。
3、大数据一体机
这是一种专为大数据的分析处理而设计的软、硬件结合的产品。它由一组集成的服务器、存储设备、操作系统、数据库管理系统,以及为数据查询、处理、分析而预安装和优化的软件组成,具有良好的稳定性和纵向扩展性。
四、大数据分析挖掘
从可视化分析、数据挖掘算法、预测性分析、语义引擎、数据质量管理等方面,对杂乱无章的数据,进行萃取、提炼和分析的过程。
1、可视化分析
可视化分析,指借助图形化手段,清晰并有效传达与沟通信息的分析手段。主要应用于海量数据关联分析,即借助可视化数据分析平台,对分散异构数据进行关联分析,并做出完整分析图表的过程。
具有简单明了、清晰直观、易于接受的特点。
2、数据挖掘算法
数据挖掘算法,即通过创建数据挖掘模型,而对数据进行试探和计算的,数据分析手段。它是大数据分析的理论核心。
数据挖掘算法多种多样,且不同算法因基于不同的数据类型和格式,会呈现出不同的数据特点。但一般来讲,创建模型的过程却是相似的,即首先分析用户提供的数据,然后针对特定类型的模式和趋势进行查找,并用分析结果定义创建挖掘模型的最佳参数,并将这些参数应用于整个数据集,以提取可行模式和详细统计信息。
3、预测性分析
预测性分析,是大数据分析最重要的应用领域之一,通过结合多种高级分析功能(特别统计分析、预测建模、数据挖掘、文本分析、实体分析、优化、实时评分、机器学习等),达到预测不确定事件的目的。
帮助分用户析结构化和非结构化数据中的趋势、模式和关系,并运用这些指标来预测将来事件,为采取措施提供依据。
4、语义引擎
语义引擎,指通过为已有数据添加语义的操作,提高用户互联网搜索体验。
5、数据质量管理
指对数据全生命周期的每个阶段(计划、获取、存储、共享、维护、应用、消亡等)中可能引发的各类数据质量问题,进行识别、度量、监控、预警等操作,以提高数据质量的一系列管理活动。
以上是从大的方面来讲,具体来说大数据的框架技术有很多,这里列举其中一些:
文件存储:Hadoop HDFS、Tachyon、KFS
离线计算:Hadoop MapReduce、Spark
流式、实时计算:Storm、Spark Streaming、S4、Heron
K-V、NOSQL数据库:HBase、Redis、MongoDB
资源管理:YARN、Mesos
日志收集:Flume、Scribe、Logstash、Kibana
消息系统:Kafka、StormMQ、ZeroMQ、RabbitMQ
查询分析:Hive、Impala、Pig、Presto、Phoenix、SparkSQL、Drill、Flink、Kylin、Druid
分布式协调服务:Zookeeper
集群管理与监控:Ambari、Ganglia、Nagios、Cloudera Manager
数据挖掘、机器学习:Mahout、Spark MLLib
数据同步:Sqoop
任务调度:Oozie
大数据包括哪些?
简单来说,从大数据的生命周期来看,无外乎四个方面:大数据采集、大数据预处理、大数据存储、大数据分析,共同组成了大数据生命周期里最核心的技术,下面分开来说:
一、大数据采集
大数据采集,即对各种来源的结构化和非结构化海量数据,所进行的采集。
数据库采集:流行的有Sqoop和ETL,传统的关系型数据库MySQL和Oracle 也依然充当着许多企业的数据存储方式。当然了,目前对于开源的Kettle和Talend本身,也集成了大数据集成内容,可实现hdfs,hbase和主流Nosq数据库之间的数据同步和集成。
网络数据采集:一种借助网络爬虫或网站公开API,从网页获取非结构化或半结构化数据,并将其统一结构化为本地数据的数据采集方式。
文件采集:包括实时文件采集和处理技术flume、基于ELK的日志采集和增量采集等等。
数据清理:指利用ETL等清洗工具,对有遗漏数据(缺少感兴趣的属性)、噪音数据(数据中存在着错误、或偏离期望值的数据)、不一致数据进行处理。
数据集成:是指将不同数据源中的数据,合并存放到统一数据库的,存储方法,着重解决三个问题:模式匹配、数据冗余、数据值冲突检测与处理。
数据转换:是指对所抽取出来的数据中存在的不一致,进行处理的过程。它同时包含了数据清洗的工作,即根据业务规则对异常数据进行清洗,以保证后续分析结果准确性。
数据规约:是指在最大限度保持数据原貌的基础上,最大限度精简数据量,以得到较小数据集的操作,包括:数据方聚集、维规约、数据压缩、数值规约、概念分层等。
二、大数据预处理
大数据预处理,指的是在进行数据分析之前,先对采集到的原始数据所进行的诸如“清洗、填补、平滑、合并、规格化、一致性检验”等一系列操作,旨在提高数据质量,为后期分析工作奠定基础。数据预处理主要包括四个部分:数据清理、数据集成、数据转换、数据规约。
三、大数据存储
大数据存储,指用存储器,以数据库的形式,存储采集到的数据的过程,包含三种典型路线:
1、基于MPP架构的新型数据库集群
采用Shared Nothing架构,结合MPP架构的高效分布式计算模式,通过列存储、粗粒度索引等多项大数据处理技术,重点面向行业大数据所展开的数据存储方式。具有低成本、高性能、高扩展性等特点,在企业分析类应用领域有着广泛的应用。
较之传统数据库,其基于MPP产品的PB级数据分析能力,有着显著的优越性。自然,MPP数据库,也成为了企业新一代数据仓库的最佳选择。
2、基于Hadoop的技术扩展和封装
基于Hadoop的技术扩展和封装,是针对传统关系型数据库难以处理的数据和场景(针对非结构化数据的存储和计算等),利用Hadoop开源优势及相关特性(善于处理非结构、半结构化数据、复杂的ETL流程、复杂的数据挖掘和计算模型等),衍生出相关大数据技术的过程。
伴随着技术进步,其应用场景也将逐步扩大,目前最为典型的应用场景:通过扩展和封装 Hadoop来实现对互联网大数据存储、分析的支撑,其中涉及了几十种NoSQL技术。
3、大数据一体机
这是一种专为大数据的分析处理而设计的软、硬件结合的产品。它由一组集成的服务器、存储设备、操作系统、数据库管理系统,以及为数据查询、处理、分析而预安装和优化的软件组成,具有良好的稳定性和纵向扩展性。
四、大数据分析挖掘
从可视化分析、数据挖掘算法、预测性分析、语义引擎、数据质量管理等方面,对杂乱无章的数据,进行萃取、提炼和分析的过程。
1、可视化分析
可视化分析,指借助图形化手段,清晰并有效传达与沟通信息的分析手段。主要应用于海量数据关联分析,即借助可视化数据分析平台,对分散异构数据进行关联分析,并做出完整分析图表的过程。
具有简单明了、清晰直观、易于接受的特点。
2、数据挖掘算法
数据挖掘算法,即通过创建数据挖掘模型,而对数据进行试探和计算的,数据分析手段。它是大数据分析的理论核心。
数据挖掘算法多种多样,且不同算法因基于不同的数据类型和格式,会呈现出不同的数据特点。但一般来讲,创建模型的过程却是相似的,即首先分析用户提供的数据,然后针对特定类型的模式和趋势进行查找,并用分析结果定义创建挖掘模型的最佳参数,并将这些参数应用于整个数据集,以提取可行模式和详细统计信息。
3、预测性分析
预测性分析,是大数据分析最重要的应用领域之一,通过结合多种高级分析功能(特别统计分析、预测建模、数据挖掘、文本分析、实体分析、优化、实时评分、机器学习等),达到预测不确定事件的目的。
帮助分用户析结构化和非结构化数据中的趋势、模式和关系,并运用这些指标来预测将来事件,为采取措施提供依据。
4、语义引擎
语义引擎,指通过为已有数据添加语义的操作,提高用户互联网搜索体验。
5、数据质量管理
指对数据全生命周期的每个阶段(计划、获取、存储、共享、维护、应用、消亡等)中可能引发的各类数据质量问题,进行识别、度量、监控、预警等操作,以提高数据质量的一系列管理活动。
以上是从大的方面来讲,具体来说大数据的框架技术有很多,这里列举其中一些:
文件存储:Hadoop HDFS、Tachyon、KFS
离线计算:Hadoop MapReduce、Spark
流式、实时计算:Storm、Spark Streaming、S4、Heron
K-V、NOSQL数据库:HBase、Redis、MongoDB
资源管理:YARN、Mesos
日志收集:Flume、Scribe、Logstash、Kibana
消息系统:Kafka、StormMQ、ZeroMQ、RabbitMQ
查询分析:Hive、Impala、Pig、Presto、Phoenix、SparkSQL、Drill、Flink、Kylin、Druid
分布式协调服务:Zookeeper
集群管理与监控:Ambari、Ganglia、Nagios、Cloudera Manager
数据挖掘、机器学习:Mahout、Spark MLLib
数据同步:Sqoop
任务调度:Oozie
······
想要学习更多关于大数据的知识可以加群和志同道合的人一起交流一下啊[https://sourl.cn/d9wRmb ]
大数据好学吗?
大数据工程师需要具备哪些能力?
数学及统计学相关的背景;
计算机编码能力;
对特定应用领域或行业的知识。
数据获取:日志收集 Scribe、Flume和爬虫等;
数据处理:流式计算的storm, spark streaming、Hadoop、消息队列相关的如Kafka等;
数据分析:HIVE、SPARK、基本算法、数据结构等;
数据存储:HDFS等;
数据挖掘:机器学习相关算法,聚类、时间序列、推荐系统、回归分析、文本挖掘、贝叶斯分类、神经网络等。
大数据工程师这个角色很重要的一点是,不能脱离市场,因为大数据只有和特定领域的应用结合起来才能产生价值。
所以,在某个或多个垂直行业的经历能为应聘者积累对行业的认知,对于之后成为大数据工程师有很大帮助,因此这也是应聘这个岗位时较有说服力的加分项。
大数据相关的技能很多,按照数据本身,可以分为数据获取、数据处理、数据分析、数据存储、数据挖掘,共5类。
希望对您有所帮助!~
相关文章
-
系统在传输封装数据时,系统是怎么解详细阅读

-
用eclipse和SQL实现工资管理系统详细阅读
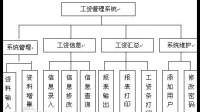
怎么用java+sql数据库做一个工资管理系统?第一章 需求分析 1.1 功能要求 1.1.1 功能概况 本次设计要求运用面向对象设计知识,利用 JAVA 语言设计实现一个“小型公司工资管理系
- 详细阅读
-
条码采集枪快递用 连接电脑 如何让详细阅读

刚买的条码枪,扫描后数据不能在电脑上显示,如何设置?条码枪一般是枪与线分开的,同一型号,枪本身是相同的,线可以是各种类型,ps2, usb, 串口等。用不同的线时,需要对枪进行设置,设置的
-
在StuDB数据库中存在两个表,详细阅读
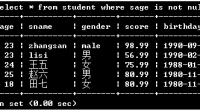
在Student数据库创建数据表 创建两个数据库,分别为Student和Class两个表1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 --创建一个名称为student的数据库 CREATE DATA
-
山海通网络科技 联盟商家的消费数详细阅读
山东山海通网络科技有限公司怎么样?简介:山东山海通网络科技有限公司,成立于2016年5月16日,位于山东省烟台市莱山区迎春大街133号附1号科技创业大厦C座212室,是专门为商家提供互
-
零基础的小白学那个编程语言,最容易详细阅读

零基础入门学习什么编程语言比较好如果你想学习编程,虽然选择第一门编程语言与你想用它来做什么最终达到什么目的有很大的关系,但是事实上某些编程语言的确比其他语言要好学。
-
请高手写出此数据号码的重号左右邻详细阅读
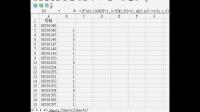
如何在EXCEL中把重复的号码显示出来,两个方法: 1.选中数据列-->在工具栏点条件格式(如果没有这个工具,请在自定义中找出来拖放到工具栏,以便以后使用)-->项目选取规则-->其他
-
数据库加密产品中的的漏扫任务,数据详细阅读

数据库加密产品中的的漏扫任务,是否有对数据库压力的风险,执行任务应该有哪些注意事项?漏扫,对于数据库服务器来说,影响忽略不计。资产梳理敏感数据扫描,也是我司设
- 详细阅读
