如何查看视频监控系统硬盘容量以硬盘录像机为例,打开监控画面,然后点击右键,再点击回放右下角有24个格,每个格是一个小时,然后点击需要回放的时间段即可怎么查电脑监控内存大小程
豆瓣每次打开都提示非法请求
互联网
2025-10-28
打开豆瓣网站显示“检测到有异常请求从你的 IP 发出,请 登录 使用豆瓣。”
1、假的提示信息,关闭即可,当广告吧 2、这个是豆瓣为了推广下载app的推广策略,比较low 提示信息一般右上角有一个颜色很淡的关闭按钮,直接关了,供参考!为什么登录都登不进去,会弹出这个“非法请求”?怎么回事阿??
12306抢票的人太多,导致服务器数据刷新还快的,而你这边的是客户端,客户端还保留着之前的数据,哪怕是前一秒都是缓存数据,这样你的浏览器里的是滞留的数据,而你又提交买票请求,这样导致了你这边的买的票可能应该被别人买了,服务器也刷新了,所以服务器返回非法请求,只能你刷新网页,或是点查票再点预订或是重新登录(但这样浪费时间),这样就没提示非法请求了。如能帮到你,请采纳为什么打开豆瓣的网页,就出现403forbidden,哪位高人有解决方法,谢谢了!
这几天刚接手一批新做的网站,在访问网站的时候,会时不时的出现403 Forbidden错误,浏览器会给出403 Forbidden错误提示,在打开Access Error中列出的URL之后, 出现以下错误: 403 Forbidden Access to this resource on the server is denied! Powered By LiteSpeed Web Server LiteSpeed Technologies is not responsible for administration and contents of this web site! 403错误是网站访为什么我显示非法请求
1、可能是手机系统的问题,建议升级至最新版本。 2、可能是手机屏幕的问题,建议更换屏幕。 3、可能是手机软件与系统冲突,建议检查软件之后进行卸载,然后关机重启。 4、可能是手机内部排线出现问题,建议送至手机维修店进行维护。 通过上面方式对手机进行检查后,能确定是手机屏幕的问题的话,建议送至苹果手机售后服务店对手机进行维修。python爬虫怎么处理豆瓣网页异常请求
1.URLError
首先解释下URLError可能产生的原因:
网络无连接,即本机无法上网
连接不到特定的服务器
服务器不存在
在代码中,我们需要用try-except语句来包围并捕获相应的异常。下面是一个例子,先感受下它的风骚
Python
1
2
3
4
5
6
7
import urllib2
requset = urllib2.Request('http://www.xxxxx.com')
try:
urllib2.urlopen(requset)
except urllib2.URLError, e:
print e.reason
我们利用了 urlopen方法访问了一个不存在的网址,运行结果如下:
Python
1
[Errno 11004] getaddrinfo failed
它说明了错误代号是11004,错误原因是 getaddrinfo failed
2.HTTPError
HTTPError是URLError的子类,在你利用urlopen方法发出一个请求时,服务器上都会对应一个应答对象response,其中它包含一个数字”状态码”。举个例子,假如response是一个”重定向”,需定位到别的地址获取文档,urllib2将对此进行处理。
其他不能处理的,urlopen会产生一个HTTPError,对应相应的状态吗,HTTP状态码表示HTTP协议所返回的响应的状态。下面将状态码归结如下:
100:继续 客户端应当继续发送请求。客户端应当继续发送请求的剩余部分,或者如果请求已经完成,忽略这个响应。
101: 转换协议 在发送完这个响应最后的空行后,服务器将会切换到在Upgrade 消息头中定义的那些协议。只有在切换新的协议更有好处的时候才应该采取类似措施。
102:继续处理 由WebDAV(RFC 2518)扩展的状态码,代表处理将被继续执行。
200:请求成功 处理方式:获得响应的内容,进行处理
201:请求完成,结果是创建了新资源。新创建资源的URI可在响应的实体中得到 处理方式:爬虫中不会遇到
202:请求被接受,但处理尚未完成 处理方式:阻塞等待
204:服务器端已经实现了请求,但是没有返回新的信 息。如果客户是用户代理,则无须为此更新自身的文档视图。 处理方式:丢弃
300:该状态码不被HTTP/1.0的应用程序直接使用, 只是作为3XX类型回应的默认解释。存在多个可用的被请求资源。 处理方式:若程序中能够处理,则进行进一步处理,如果程序中不能处理,则丢弃
301:请求到的资源都会分配一个永久的URL,这样就可以在将来通过该URL来访问此资源 处理方式:重定向到分配的URL
302:请求到的资源在一个不同的URL处临时保存 处理方式:重定向到临时的URL
304:请求的资源未更新 处理方式:丢弃
400:非法请求 处理方式:丢弃
401:未授权 处理方式:丢弃
403:禁止 处理方式:丢弃
404:没有找到 处理方式:丢弃
500:服务器内部错误 服务器遇到了一个未曾预料的状况,导致了它无法完成对请求的处理。一般来说,这个问题都会在服务器端的源代码出现错误时出现。
501:服务器无法识别 服务器不支持当前请求所需要的某个功能。当服务器无法识别请求的方法,并且无法支持其对任何资源的请求。
502:错误网关 作为网关或者代理工作的服务器尝试执行请求时,从上游服务器接收到无效的响应。
503:服务出错 由于临时的服务器维护或者过载,服务器当前无法处理请求。这个状况是临时的,并且将在一段时间以后恢复。
HTTPError实例产生后会有一个code属性,这就是是服务器发送的相关错误号。
因为urllib2可以为你处理重定向,也就是3开头的代号可以被处理,并且100-299范围的号码指示成功,所以你只能看到400-599的错误号码。
下面我们写一个例子来感受一下,捕获的异常是HTTPError,它会带有一个code属性,就是错误代号,另外我们又打印了reason属性,这是它的父类URLError的属性。
Python
1
2
3
4
5
6
7
8
import urllib2
req = urllib2.Request('httt/cqcre')
try:
urllib2.urlopen(req)
except urllib2.HTTPError, e:
print e.code
print e.reason
运行结果如下
Python
1
2
403
Forbidden
错误代号是403,错误原因是Forbidden,说明服务器禁止访问。
我们知道,HTTPError的父类是URLError,根据编程经验,父类的异常应当写到子类异常的后面,如果子类捕获不到,那么可以捕获父类的异常,所以上述的代码可以这么改写
Python
1
2
3
4
5
6
7
8
9
10
11
import urllib2
req = urllib2.Request('hcqcre')
try:
urllib2.urlopen(req)
except urllib2.HTTPError, e:
print e.code
except urllib2.URLError, e:
print e.reason
else:
print "OK"
如果捕获到了HTTPError,则输出code,不会再处理URLError异常。如果发生的不是HTTPError,则会去捕获URLError异常,输出错误原因。
另外还可以加入 hasattr属性提前对属性进行判断,代码改写如下
Python
1
2
3
4
5
6
7
8
9
10
11
12
import urllib2
req = urllib2.Request('httcqcre')
try:
urllib2.urlopen(req)
except urllib2.URLError, e:
if hasattr(e,"code"):
print e.code
if hasattr(e,"reason"):
print e.reason
else:
print "OK"
首先对异常的属性进行判断,以免出现属性输出报错的现象。
以上,就是对URLError和HTTPError的相关介绍,以及相应的错误处理办法,小伙伴们加油!
相关文章
- 详细阅读
-
全民k歌电脑版本只有2.2;手机的版本详细阅读

全民k歌提示版本低上不去怎么办1、打开手机界面,找到“全民K歌”软件2、打开全民K歌后,切换到“我的”选项3、在我的界面中,找到左上角的“设置”选项4、在设置的界面中,用手指
-
求一张海贼王电脑桌面详细阅读

求海贼王草帽海贼团的1366*768的电脑桌面壁纸海贼王草帽海贼团的1366*768的电脑桌面壁纸如下:草帽一伙是日本漫画《航海王》中主人公蒙奇·D·路飞所集结的海贼团,旗帜图案是
-
电脑本版的迷你世界移动不了怎么办详细阅读

为什么电脑玩迷你世界按w走不了用电脑玩迷你世界不能行走是因为电脑程序里没有设置行走。
在迷你世界中,先按一次前进键,就是W键,然后在按住前进键就能够实现往前疾跑。后退也 -
为什么360网和好123网不好下载电脑详细阅读
怎么下载拼多多 电脑版拼多多下载的方法下载拼多多可以用电脑或者手机,但只有Android版、iPhone版和iPad版,没有你说的电脑端,下面教一下电脑下载拼多多和手机下载拼多多的步骤
-
电脑自动输入mc39详细阅读
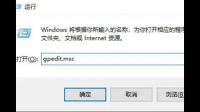
电脑键盘自动输入不停怎么办?键盘自动输入不停,可以按键盘上的组合键来打开策略组编辑器,Windows更新中的启用配置自动更新来解决,方法如下:工具/原料:华硕飞7、Windows10、本地设
-
漫步者r208pf线控怎么播放电脑音乐详细阅读

漫步者音响怎么连接电脑方法如下:漫步者电脑音箱安装到电脑上,需要将漫步者音箱的音频线连接音箱输入和电脑音频输出孔。一、连接示意图:二、连接说明:1、电脑正常开启,漫步者音
-
电脑开机后一直卡在这个界面详细阅读

电脑开机后一直卡在这个界面,怎么办?1、首先我们直接按主机重启按钮,然后重启的开机的时候按F8,进入到启动模式选择界面,我们点击【安全模式】,通过安全模式可以更快的进入到桌面
-
电脑用优化大师,优化了,后电脑就有点详细阅读

为什么用了优化大师之后电脑反而变得卡了?一般来说,所谓的优化,就是对系统DLL文件进行处理,但许多时候,软件并不是智能的,所以会对一些有用的DLL等系统文件PK,造成系统问题!!!慎用啊~~
-
学习电脑技术大概要多少费用啊?详细阅读

想报一个电脑培训班要多少钱?电脑培训从3000元—30000元不等,电脑培训班要多少钱与培训课程专业和学员自身有关,主要是专业和时间。具体分析如下: 1、初级电脑培训班:初级电脑培