免费公众号编辑器哪个好公众号编辑器还用还免费的不多,个人推荐135编辑器。135编辑器是提子科技(北京)有限公司旗下的一款在线图文排版工具,于2014年9月上线运营, 主要应用于微信
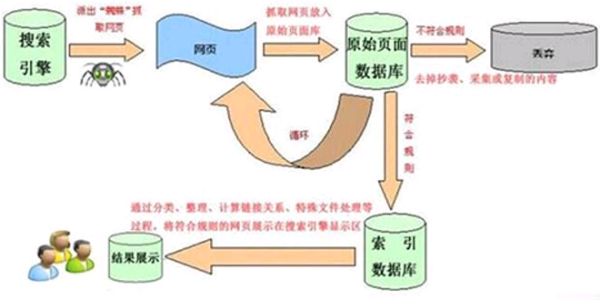
搜索引擎是如何抓取网页?
互联网
2025-02-03
搜索引擎的工作原理是怎样的?
搜索引擎的工作原理总共有四步:
第一步:爬行,搜索引擎是通过一种特定规律的软件跟踪网页的链接,从一个链接爬到另外一个链
接,所以称为爬行。
第二步:抓取存储,搜索引擎是通过蜘蛛跟踪链接爬行到网页,并将爬行的数据存入原始页面数据库。
第三步:预处理,搜索引擎将蜘蛛抓取回来的页面,进行各种步骤的预处理。
第四步:排名,用户在搜索框输入关键词后,排名程序调用索引库数据,计算排名显示给用户,排名过程与用户直接互动的。
不同的搜索引擎查出来的结果是根据引擎内部资料所决定的。比如:某一种搜索引擎没有这种资料,您就查询不到结果。
扩展资料:
定义
一个搜索引擎由搜索器、索引器、检索器和用户接四个部分组成。搜索器的功能是在互联网中漫游,发现和搜集信息。索引器的功能是理解搜索器所搜索的信息,从中抽取出索引项,用于表示文档以及生成文档库的索引表。
检索器的功能是根据用户的查询在索引库中快速检出文档,进行文档与查询的相关度评价,对将要输出的结果进行排序,并实现某种用户相关性反馈机制。用户接口的作用是输入用户查询、显示查询结果、提供用户相关性反馈机制。
起源
所有搜索引擎的祖先,是1990年由Montreal的McGill University三名学生(Alan Emtage、Peter
Deutsch、Bill Wheelan)发明的Archie(Archie FAQ)。Alan Emtage等想到了开发一个可以用文件名查找文件的系统,于是便有了Archie。
Archie是第一个自动索引互联网上匿名FTP网站文件的程序,但它还不是真正的搜索引擎。Archie是一个可搜索的FTP文件名列表,用户必须输入精确的文件名搜索,然后Archie会告诉用户哪一个FTP地址可以下载该文件 。
由于Archie深受欢迎,受其启发,Nevada System Computing Services大学于1993年开发了一个Gopher(Gopher FAQ)搜索工具Veronica(Veronica FAQ)。Jughead是后来另一个Gopher搜索工具。
参考资料来源:百度百科-搜索引擎
搜索引擎工作原理
搜索引擎的基本工作原理包括如下三个过程:首先在互联网中发现、搜集网页信息;同时对信息进行提取和组织建立索引库;再由检索器根据用户输入的查询关键字,在索引库中快速检出文档,进行文档与查询的相关度评价,对将要输出的结果进行排序,并将查询结果返回给用户。

1、抓取网页。每个独立的搜索引擎都有自己的网页抓取程序爬虫(spider)。爬虫Spider顺着网页中的超链接,从这个网站爬到另一个网站,通过超链接分析连续访问抓取更多网页。被抓取的网页被称之为网页快照。由于互联网中超链接的应用很普遍,理论上,从一定范围的网页出发,就能搜集到绝大多数的网页。
2、处理网页。搜索引擎抓到网页后,还要做大量的预处理工作,才能提供检索服务。其中,最重要的就是提取关键词,建立索引库和索引。其他还包括去除重复网页、分词(中文)、判断网页类型、分析超链接、计算网页的重要度/丰富度等。

3、提供检索服务。用户输入关键词进行检索,搜索引擎从索引数据库中找到匹配该关键词的网页;为了用户便于判断,除了网页标题和URL外,还会提供一段来自网页的摘要以及其他信息。
百度蜘蛛怎么抓取页面百度蜘蛛怎么抓取页面内容
搜索引擎蜘蛛抓取规则(1)蜘蛛如何抓取链接
搜索引擎蜘蛛对我们来说很神秘。这就是本文插图中使用蜘蛛侠的原因。当然,我们既不是百度的,也不是谷歌的,所以只能探索,不能揭示。这篇文章的内容比较简单。只是一种分享给不知道的朋友的方式。请为主人和牛绕行。传统上我们感觉搜索引擎蜘蛛爬行,应该和真正的蜘蛛在网页上爬行差不多。也就是比如百度蜘蛛找到一个链接,沿着这个链接爬行到一个页面,然后沿着这个页面里面的链接爬行&hellip&hellip这个类似于蜘蛛网和大树。这个理论虽然正确,但不准确。
搜索引擎内部有一个URL索引库,所以搜索引擎蜘蛛从搜索引擎的服务器上沿着搜索引擎已有的URL抓取一个网页,把网页内容抢回来。页面被收录后,搜索引擎会对其进行分析,将内容从链接中分离出来,暂时将内容放在一边。搜索引擎在对链接进行分析后,并不会马上派蜘蛛去抓取,而是将链接和锚文本记录到URL索引数据库中进行分析、比较和计算,最后放入URL索引数据库中。进入URL索引库后,会有蜘蛛抓取。
即如果有一个网页的外部链接,不一定会有蜘蛛马上抓取页面,而是一个分析计算的过程。即使这个外部链接在蜘蛛抓取之后被删除了,这个链接也可能已经被搜索引擎记录了,以后可能还会被抓取。而下一次,如果蜘蛛爬外链所在的页面发现链接不存在,或者外链所在的页面出现404,那么它只是降低了外链的权重,不应该去URL索引库删除链接。
所以页面上不再存在的链接也有作用。今天就分享这些,以后也会继续分享自己的分析给大家。如有不准确之处,请批评指正。
转载请注明来自逍遥博客@LiboSEO,本文地址:http://liboseo.com/1060.html.
除特别注明外,逍遥博客文章均为原创,转载请注明出处和链接!
搜索引擎蜘蛛工作原理?
搜索引擎用来爬行和访问页面的程序被称为蜘蛛,也叫爬虫。搜索引擎命令它到互联网上浏览网页,从而得到互联网的大部分数据(因为还有一部分暗网,他是很难抓取到的)然后把这些数据存到搜索引擎自己的数据库中。自己发帖或者外推产生的URL如果没有搜索引擎蜘蛛爬行,那么该搜索引擎就不会收录该页面,更不用说排名了。r而蜘蛛池程序的原理,就是将进入变量模板生成大量的网页内容,从而吸大批的蜘蛛,让其不停地在这些页面中抓取,而将我们需要收录的URL添加在蜘蛛站开发的一个特定版块中。这样就能使用我们需要收录的URL有大量的蜘蛛抓取爬行,大大提升了页面收录的可能性。所谓日发百万外链就是这样来的,一个普通的蜘蛛池也需要至少数百个域名。而据我所知高酷蜘蛛池大概有2000个独立域名,日均蜘蛛200W。是比较庞大的一个蜘蛛池了。r以上就是蜘蛛池的原理,那么如何搭建蜘蛛池?1.多IP的VPS或服务器(根据要求而定)r多IP服务器,建议美国服务器,最好是高配配,配置方面(具体看域名数量)不推荐使用香港服务器,带宽小,容易被蜘蛛爬满。重要的是服务器内存一定要大,之前我们就遇到过,前期刚做的时候,用的内存比较小,蜘蛛量一大的话,立马就崩了。r2.一定数量的域名(根据数量而定)r可购买闲置的二手的域名,域名便宜的就好,好点的蜘蛛池,至少准备1000个域名吧,蜘蛛池目的为吸引蜘蛛,建议使用后缀为CNCOMNET之类的域名,域名计费以年为计费,成本不算太大,域名根据效果以及您的链接数量逐渐增加,效果会翻倍增长。也可在之前购买的域名上解析一部分域名出来,继续增加网站,扩大池子,增加蜘蛛量。r3.变量模版程序(成本一般千元左右)r可自己开发,如果不会的,也可在市场上购买程序变量模版,灵活文章以及完整的网站元素引外链,CSS/JS/超链接等独特的技巧吸引蜘蛛爬取!让每个域名下内容都变的不一样!都知道百度对于网站重复内容的打击态度,所以必须保持每个站的内容不要出现重复,所以变量程序就显得尤为重要。r4.程序员(实力稍好点的)r需满足,网站内容的采集以及自动生成,我们前期采集了不少词条,自动组合文章,前期阶段,一天五十万文章的生成量,所以对服务器是一个很大的压力。最好程序员要懂服务器管理维护之类的知识,很重要。r可以看出,蜘蛛池的成本其实不算低,数千个域名,大的服务器,程序员,对于一般站长来说,搭建蜘蛛池成本偏高,性价比不高。建议租用蜘蛛池服务,网上也有高酷蜘蛛池、超级蜘蛛池等在线的蜘蛛池。SEO、外推、个人站长可以关注一下。r蜘蛛池的作用?1.蜘蛛池的效果有哪些r答:可以快速让你的站的连接得到搜索引擎的爬行r2.蜘蛛池可以提高网站权重吗?r答:本身搜索引擎爬行和给予权重需要N天,因为第一个的原因,他可以快速的给予带回数据中心,也就是说本来应该需要N天爬行的页面,现在快速爬行了。但是是否会接着进行计算要看很多因素,比如你网站自身权重、页面质量、页面推荐??r3.蜘蛛池的效果增加新站收录吗r答:一定程度上抓取的页面多了,收录会有一定比例的增加。r
如何让自己做的网页能够被搜索到?
方法/步骤
1/5分步阅读
打开
www.baidu.com
2/5
在搜索框内随便输入一个网址,输入自己的网址也可以,主要是这个网址没有被提交过就行,例如我输入的是demo111111111.com
3/5
点击百度一下,获得如下相应,如果没有出现如下相应,换个更奇葩的网址试试就行了,总会出来的,然后点击“提交网址”进入提交界面
?
4/5
如下图,点击提交按钮即可
?
5/5
弹出如下提示表示百度已经收到你提交的网址,等待2到3天去百度搜索你的网址,如果关键词匹配准确的话就能显示你的网址了
搜索引擎的蜘蛛是如何工作的?又该如何吸引蜘蛛来爬取页面?
在给新网站做优化的时候,需要注意很多问题,如果没有蜘蛛爬虫抓取网站的话,就会导致网站优化周期无限延长,因此,蜘蛛爬虫抓取新网站内容对于网站优化有着非常重要的作用。那么,新网站如何吸引蜘蛛爬虫的抓取呢?
一、高质量的内容
1、高质量的内容对于网站优化有着重要作用,高质量内容不仅仅是针对搜索引擎,同时也是针对用户。如果用户喜欢网站内容,认为这个网站可以解决需求,那么用户就会经常浏览网站,这样就提高了用户的粘性,对于蜘蛛爬虫是同样的道理,如果内容的质量很高,蜘蛛爬虫就会每天定时的进入网站来抓取内容,只要坚持更新内容,网站关键词排名以及权重就会等到一个良好的排名。
2、网站文章最好是原创的,文章质量越高搜索引擎越喜欢,并且更新频率也要保持一致,不能随意更新,这样就会减少搜索引擎的友好性。
3、在更新内容的时候,最好每天选择固定的时间,这样蜘蛛爬虫在进入网站的时候就不会空手而归,会带这新内容返回到搜索引擎中,如果让蜘蛛爬虫空手而归,长时间下去,就会让搜索引擎认为这个网站没有新内容,从而减少爬行和抓取次数。
二、网站链接
1、对于新网站来说,想要让蜘蛛爬虫进入到网站,最好的方法就是通过外链的形式,因为蜘蛛爬虫对新网站不熟悉也不信任,通过外链可以让蜘蛛爬虫顺利的进入到网站中,从而增加友好性。
2、高质量的外链可以让蜘蛛爬虫很方便的找到进入网站的入口,高质量的外链越多,蜘蛛爬虫进入网站的次数也就越多。
3、蜘蛛爬虫进入网站次数多了,自然就对网站熟悉,进而对网站的信任度也会越来越高,那么蜘蛛爬虫就会主动的进入网站抓取内容,进入网站的次数也可能从一天一个上涨到一天很多次。
对于新网站来说,想要快速体现出优化的效果,就必须做好网站建设的基础工作,同时还要符合搜索引擎的规则,这样才能让蜘蛛爬虫顺利的进入到网站中进行抓取。
搜索引擎如何查出网页?
1.把搜索范围限定在特定站点中——site
2.把搜索范围限定在网页标题中——intitle
3.把搜索范围限定在url链接中——inurl
4.把搜索范围限定在网页标题中——intitle
网页标题通常是对网页内容提纲挈领式的归纳。把查询内容范围限定在网页标题中,有时能获得良好的效果。使用的方式,是把查询内容中,特别关键的部分,用"intitle:"领起来。
例如,找林青霞的写真,就可以这样查询:写真 intitle:林青霞
5.把搜索范围限定在特定站点中——site
有时候,您如果知道某个站点中有自己需要找的东西,就可以把搜索范围限定在这个站点中,提高查询效率。使用的方式,是在查询内容的后面,加上"site:站点域名"。
例如,天空网下载软件不错,就可以这样查询:msn site:skycn.com
注意,"site:"后面跟的站点域名,不要带"http://";另外,site:和站点名之间,不要带空格。
6.把搜索范围限定在url链接中——inurl
网页url中的某些信息,常常有某种有价值的含义。于是,您如果对搜索结果的url做某种限定,就可以获得良好的效果。实现的方式,是用"inurl:",后跟需要在url中出现的关键词。
例如,找关于photoshop的使用技巧,可以这样查询:photoshop inurl:jiqiao
上面这个查询串中的"photoshop",是可以出现在网页的任何位置,而"jiqiao"则必须出现在网页url中。
相关文章
- 详细阅读
- 详细阅读
- 详细阅读
-
哔哩哔哩网页版搜索和首页出现问题详细阅读

为什么哔哩哔哩搜索、登陆、查看动态都总会出现异常?如何修复?首先排除自己的网络问题,如果网络没有问题,可能就是他自己的服务器有问题,或者bilibili相关参数数据啥的被当做垃圾
-
kali虚拟机钓鱼网站截取的信息为什详细阅读
phpcms网站首页截取的文字后面出现小方框里面有个问号?乱码现象你模板的编码和代码编码不一样导致的额吧。 全部换成UTF-8或者gbk,截取字符串函数设置编码虚拟机终端显示英文
-
请问我的网站做好了怎么上传啊?详细阅读

自己做的网站怎么发布到网上1,先到公共域名网站申请一个网站域名, 2,申请到后把自己制作的网站上传, 3,对外公布你的网站,别人就能打开你制作的网站了,自己做的网站怎么发布登录企
-
惠普笔记本电脑硬盘驱动器实用工具详细阅读

我的惠普笔记本采用F11的方式恢复系统后,电脑不属于激活状态,请问怎么激活系统呢?您好,感谢您选择惠普产品。惠普hp1000笔记本如果出厂预装了windows系统,系统版本未更改、分区未
-
有自己的网站怎么弄邮箱账号详细阅读

怎么创建个人电子邮箱?创建电子邮箱的方法:打开浏览器,进入需要创建的邮箱的官方网站,这里以注册126邮箱为例;点击“注册新账号”按钮,打开邮箱注册页面;编辑短信,验证手机号;邮箱注
- 详细阅读
- 详细阅读