Java代码错误原因是啥原因可能为: 1、运行的用户数过多,对服务器造成的压力过大,服务器无法响应,则报HTTP500错误。减小用户数或者场景持续时间,问题得到解决。 2、该做关联的地
为什么在这个例子中,不能用silhouette_score对DBSCAN评价?
软件
2025-01-14
聚类评价指标-轮廓系数
评估聚类算法的性能并不像计算错误数量或监督分类算法的精度和召回率那么简单。特别是任何评价指标不应考虑集群的绝对值的标签,而是如果这个集群定义分离的数据类似于一些地标准数据类或满足一些假设,根据某种相似性度量,这样成员属于同一类相似度大于不同的类的成员。Silhouette Coefficient
如果真实的标签不知道,评估必须使用模型本身来执行。轮廓系数(sklearn.metrics. Silhouette ette_score)就是这种评价的一个例子,轮廓系数得分越高,表示具有定义的聚类的模型越好。定义每个样本的轮廓系数,由两个分值组成
a:一个样本与同类中所有其它点之间的平均距离。一个样本与同类中所有其它点之间的平均距离。
b:样本与下一个最近聚类中所有其它点之间的平均距离。
则单样本的轮廓系数s为:
例子
注意
1 不正确的聚类得分为-1,而高度密集的聚类得分为+1。0左右的分数表示重叠的集群
2 当集群密集且分离良好时,得分较高,这与集群的标准概念有关
3 如基于密度的簇,如通过DBSCAN得到的簇的轮廓系数通常高于其他概念的簇。
来源 :sklearn官网
地址: https://scikit-learn.org/stable/modules/clustering.html#clustering-evaluation
常用聚类(K-means,DBSCAN)以及聚类的度量指标:
一年前需要用聚类算法时,自己从一些sklearn文档和博客粗略整理了一些相关的知识,记录在电子笔记里备忘,现在发到网上,当时就整理的就很乱,以后有空慢慢把内容整理、完善,用作备忘。之前把电影标签信息的聚类结果作为隐式反馈放进SVD++中去训练,里面有两个小例子利用条件熵定义的同质性度量:
sklearn.metrics.homogeneity_score:每一个聚出的类仅包含一个类别的程度度量。
sklearn.metrics.completeness:每一个类别被指向相同聚出的类的程度度量。
sklearn.metrics.v_measure_score:上面两者的一种折衷:
v = 2 * (homogeneity * completeness) / (homogeneity + completeness)
可以作为聚类结果的一种度量。
sklearn.metrics.adjusted_rand_score:调整的兰德系数。
ARI取值范围为[-1,1],从广义的角度来讲,ARI衡量的是两个数据分布的吻合程度
sklearn.metrics.adjusted_mutual_info_score:调整的互信息。
利用基于互信息的方法来衡量聚类效果需要实际类别信息,MI与NMI取值范围为[0,1],AMI取值范围为[-1,1]。
在scikit-learn中, Calinski-Harabasz Index对应的方法是metrics.calinski_harabaz_score.
CH指标通过计算类中各点与类中心的距离平方和来度量类内的紧密度,通过计算各类中心点与数据集中心点距离平方和来度量数据集的分离度,CH指标由分离度与紧密度的比值得到。从而,CH越大代表着类自身越紧密,类与类之间越分散,即更优的聚类结果。
silhouette_sample
对于一个样本点(b - a)/max(a, b)
a平均类内距离,b样本点到与其最近的非此类的距离。
silihouette_score返回的是所有样本的该值,取值范围为[-1,1]。
这些度量均是越大越好
K-means算法应该算是最常见的聚类算法,该算法的目的是选择出质心,使得各个聚类内部的inertia值最小化,计算方法如下:
inertia可以被认为是类内聚合度的一种度量方式,这种度量方式的主要缺点是:
(1)inertia假设数据内的聚类都是凸的并且各向同性( convex and isotropic),
各项同性是指在数据的属性在不同方向上是相同的。数据并不是总能够满足这些前提假设的,
所以当数据事细长簇的聚类,或者不规则形状的流形时,K-means算法的效果不理想。
(2)inertia不是一种归一化度量方式。一般来说,inertia值越小,说明聚类效果越好。
但是在高维空间中,欧式距离的值可能会呈现迅速增长的趋势,所以在进行K-means之前首先进行降维操作,如PCA等,可以解决高维空间中inertia快速增长的问题,也有主意提高计算速度。
K-means算法可以在足够长的时间内收敛,但有可能收敛到一个局部最小值。
聚类的结果高度依赖质心的初始化,因此在计算过程中,采取的措施是进行不止一次的聚类,每次都初始化不同的质心。
sklearn中可以通过设置参数init='kmeans++'来采取k-means++初始化方案,
即初始化的质心相互之间距离很远,这种方式相比于随机初始质心,能够取得更好的效果。
另外,sklearn中可以通过参数n_job,使得K-means采用并行计算的方式。
##sklearn 中K-means的主要参数:
1) n_clusters: 设定的k值
2)max_iter: 最大的迭代次数,一般如果是凸数据集的话可以不管这个值,如果数据集不是凸的,可能很难收敛,此时可以指定最大的迭代次数让算法可以及时退出循环。
3)n_init:用不同的初始化质心运行算法的次数。由于K-Means是结果受初始值影响的局部最优的迭代算法,因此需要多跑几次以选择一个较好的聚类效果,默认是10。如果你的k值较大,则可以适当增大这个值。
4)init: 即初始值选择的方式,可以为完全随机选择'random',优化过的'k-means++'或者自己指定初始化的k个质心。一般建议使用默认的'k-means++'。
5)algorithm:有“auto”, “full” or “elkan”三种选择。"full"就是我们传统的K-Means算法, “elkan”elkan K-Means算法。默认的"auto"则会根据数据值是否是稀疏的,来决定如何选择"full"和“elkan”。一般来说建议直接用默认的"auto"
聚类的中心
print clf.cluster_centers_
每个样本所属的簇
print clf.labels_
用来评估簇的个数是否合适,距离越小说明簇分的越好,选取临界点的簇个数
print clf.inertia_
Sum of distances of samples to their closest cluster center.
两个小例子(很久以前弄的,写得比较简略比较乱,有空再改,数据是movielen中的电影标签信息):
例1:
例2,在区间[2,200]上遍历k,并生成两个聚类内部评价指标CH分、轮廓系数以及kmeans自带inertia分和对应的k值的图片来选择k:
其中两点相似度s(i, j)的度量默认采用负欧氏距离。
sklearn.cluster.AffinityPropagation
有参数preference(设定每一个点的偏好,将偏好于跟其他节点的相似性进行比较,选择
高的作为exmplar,未设定则使用所有相似性的中位数)、damping (阻尼系数,
利用阻尼系数与1-阻尼系数对r 及 a进行有关迭代步数的凸组合,使得算法收敛
default 0.5 可以取值与[0.5, 1])
cluster_centers_indices_:中心样本的指标。
AP算法的主要思想是通过数据点两两之间传递的信息进行聚类。
该算法的主要优点是能够自主计算聚类的数目,而不用人为制定类的数目。
其缺点是计算复杂度较大 ,计算时间长同时空间复杂度大,
因此该算法适合对数据量不大的问题进行聚类分析。
数据点之间传递的信息包括两个,吸引度(responsibility)r(i,k)和归属度(availability)a(i,k)。
吸引度r(i,k)度量的是质心k应当作为点i的质心的程度,
归属度a(i,k)度量的是点i应当选择质心k作为其质心的程度。
其中t是迭代的次数,λ是阻尼因子,其值介于[0,1],在sklearn.cluster.AffinityPropagation中通过参数damping进行设置。
每次更新完矩阵后,就可以为每个数据点分配质心,分配方式?是针对数据点i,遍历所有数据点k(包括其自身),
找到一个k使得r(i,k)+a(i,k)的值最大,则点k就是点i所属的质心,迭代这个过程直至收敛。
所谓收敛就是所有点所属的质心不再变化
首先说明不引入核函数时的情况。
算法大致流程为:随机选取一个点作为球心,以一定半径画一个高维球(数据可能是高维的),
在这个球范围内的点都是这个球心的邻居。这些邻居相对于球心都存在一个偏移向量,
将这些向量相加求和再平均,就得到一个mean shift,起点在原球心,重点在球内的其他位置。
以mean shift的重点作为新的球心,重复上述过程直至收敛。
这个计算过程中,高维球内的点,无论其距离球心距离多远,对于mean shift的计算权重是一样的。
为了改善这种情况,在迭代计算mean shift的过程中引入了核函数
sklearn中相关实现是sklearn.cluster.MeanShift。
sklearn中实现的是自底向上的层次聚类,实现方法是sklearn.cluster.AgglomerativeClustering。
初始时,所有点各自单独成为一类,然后采取某种度量方法将相近的类进行合并,并且度量方法有多种选择。
合并的过程可以构成一个树结构,其根节点就是所有数据的集合,叶子节点就是各条单一数据。
sklearn.cluster.AgglomerativeClustering中可以通过参数linkage选择不同的度量方法,用来度量两个类之间的距离,
可选参数有ward,complete,average三个。
ward:选择这样的两个类进行合并,合并后的类的离差平方和最小。
complete:两个类的聚类被定义为类内数据的最大距离,即分属两个类的距离最远的两个点的距离。
选择两个类进行合并时,从现有的类中找到两个类使得这个值最小,就合并这两个类。
average:两个类内数据两两之间距离的平均值作为两个类的距离。
同样的,从现有的类中找到两个类使得这个值最小,就合并这两个类。
Agglomerative cluster有一个缺点,就是rich get richer现象,
这可能导致聚类结果得到的类的大小不均衡。
从这个角度考虑,complete策略效果最差,ward得到的类的大小最为均衡。
但是在ward策略下,affinity参数只能是“euclidean”,即欧式距离。
如果在欧氏距离不适用的环境中,average is a good alternative。
另外还应该注意参数affinity,这个参数设置的是计算两个点之间距离时采用的策略,
注意和参数linkage区分,linkage设置的是衡量两个类之间距离时采用的策略,
而点之间的距离衡量是类之间距离衡量的基础。
affinity的可选数值包括 “euclidean”, “l1”, “l2”, “manhattan”, “cosine”,
‘precomputed’. If linkage is “ward”, only “euclidean” is accepted.
DBSCAN算法的主要思想是,认为密度稠密的区域是一个聚类,各个聚类是被密度稀疏的区域划分开来的。
也就是说,密度稀疏的区域构成了各个聚类之间的划分界限。与K-means等算法相比,该算法的主要优点包括:可以自主计算聚类的数目,不需要认为指定;不要求类的形状是凸的,可以是任意形状的。
DBSCAN中包含的几个关键概念包括core sample,non-core sample,min_sample,eps。
core samle是指,在该数据点周围eps范围内,至少包含min_sample个其他数据点,则该点是core sample,
这些数据点称为core sample的邻居。与之对应的,non-sample是该点周围eps范围内,所包含的数据点个数少于min_sample个。从定义可知,core sample是位于密度稠密区域的点。
一个聚类就是一个core sample的集合,这个集合的构建过程是一个递归的构成。
首先,找到任意个core sample,然后从它的邻居中找到core sample,
接着递归的从这些邻居中的core sample的邻居中继续找core sample。
要注意core sample的邻居中不仅有其他core sample,也有一些non-core smaple,
也正是因为这个原因,聚类集合中也包含少量的non-core sample,它们是聚类中core sample的邻居,
但自己不是core sample。这些non-core sample构成了边界。
在确定了如何通过单一core sample找到了一个聚类后,下面描述DBSCAN算法的整个流程。
首先,扫描数据集找到任意一个core sample,以此core sample为起点,按照上一段描述的方法进行扩充,确定一个聚类。然后,再次扫描数据集,找到任意一个不属于以确定类别的core sample,重复扩充过程,再次确定一个聚类。
迭代这个过程,直至数据集中不再包含有core sample。
这也是为什么DBSCAN不用认为指定聚类数目的原因。
DBSCAN算法包含一定的非确定性。数据中的core sample总是会被分配到相同的聚类中的,哪怕在统一数据集上多次运行DBSCAN。其不确定性主要体现在non-core sample的分配上。
一个non-core sample可能同时是两个core sample的邻居,而这两个core sample隶属于不同的聚类。
DBSCAN中,这个non-core sample会被分配给首先生成的那个聚类,而哪个聚类先生成是随机的。
sklearn中DBSCAN的实现中,邻居的确定使用的ball tree和kd-tree思想,这就避免了计算距离矩阵。
有谁有在winform中使用ckeditor这个控件的例子?能不能给我一份?请发到我的邮箱,谢谢啦marlies@yeah.net
我有
求非财务指标在业绩评价体系中的运用的有关案例
建立国有邮政企业经营绩效评价理论框架的实质就是给国有邮政企业业绩情况制订一个共同的行业标准,再以标准的评定结果得出不同的绩效等级。绩效等级与企业等级可有机地结合起来,使不同绩效的邮政企业有着不同的等级和激励标准。这些激励标准可以包括工资增长幅度、人均工资总额、经营者的年薪所得、亏损补贴率、资金留存额度等等。在现阶段,邮政企业一方面要从分营后的亏损局面走出来,另一方面要给经营者足够的激励政策,并赋予其更广泛的经营权和理财权,比较完善的绩效评价体系成为评判业绩的有力依据。在排除各种客观因素后,每年或一段时间对邮政企业进行一次体系得分评价,并将所得的绩效等级与企业激励等级挂起钩来,将对邮政企业领导层产生更有效的激励作用。中央国有邮政企业建立绩效评价体系的必要性
1、原有的行业评价指标已经满足不了竞争性邮政业务的需要。现有的财务性业绩评价指标建立在传统会计信息基础之上,主要来源于企业损益及资产负债状况等,对企业有形资产评价处于体系中的主导地位,如收入增长率、收支差等,收入及其完成进度指标处于指标中主要地位。然而邮政企业属国家第三产业,其发展状况受其他主要产业发展影响。现代企业业绩提高与我国以工业经济发展为主导的时代相比发生了很大变化,以劳动密集型为主的邮政企业其主营收入的增长很难恢复到邮电分营前以电信发展为主导的增长幅度。随着我国经济向服务经济的发展,邮政企业已经意识到,企业要有新的发展就必须充分发挥现有的网络优势,积极加入未来以信息和知识为主导的服务经济行列。各种与之相关的非财务因素指标如技术装备、员工素质、市场份额等等在企业评价体系中应成为重要指标。
另一个重要因素是目前邮政企业的资金使用及流向与每一个多元实体经济活动是密不可分的,且对应关系很明显,经营者的批示代表的不仅是此项经济活动的可行性,而且包括其未来承担的责任。然而竞争是市场经济中表现最强的因素,经营活动不可能每次事项都与货币流动对应起来,如企业要招收的大中专院校毕业生源减少、企业与用户经营伙伴关系减少、参与社会招标竞争失败等等,传统财务数据是无法反映的,也就是说原有的指标无法反映各经营实体经济活动的全貌和实质。指标体系如果不包含非财务项目,很明显将不能反映一个国有邮政企业内部各多元实体在市场中的竞争实力,其持久的生命力情况也得不到体现。竞争使邮政企业财务评价指标不再满足对企业经营者业绩评价的需要,非财务指标如企业地区影响、发展战略、市场份额等的介入有一定的必然性。
2、建立绩效评价体系是邮政企业适应经营环境、进行正确经营决策的需要。目前,无论是评价通信收入的绝对量、相对量,还是评价业务总量,主要都是对经营成果进行的事后衡量,注重的是一年或半年甚至单月的短期财务成果,对这种过去成果的衡量,导致的往往是经营者会控制短期经营活动以维持未来短期成果达到目标需要,从长远来看,这种做法会扼制企业创造长期价值的过程,使具有未来增值能力的可行性项目、可用的人才资源、可投资的智力成果,甚至一条合理化建议,得不到必要的重视。潜在的发展能力决定邮政企业的未来发展价值,对邮政企业的综合评价就不能仅仅停留在财务账面的指标,它反映不出指标来源,衡量不出未来发展因素,在对邮政企业指标评价中加入未来发展指标的评价便必不可少。分营后的邮政企业对未来经营的预计、未来经营战略的选择,将成为邮政企业今后发展的力量来源;同时在朝着信息时代发展的过程中,知识作为企业未来发展的动力能否使企业由传统邮政向现代邮政升级转换,未来信息经济在邮政企业占有怎样的份额,这也将成为目前邮政企业在未来发展过程中必须考虑的重要因素。邮政企业这种对未来绩效的驱动因素,通过相关指标体系评价出来,作为决策需要,便成为经营发展中必不可少的内容,而且它能让人更清楚地看到企业经营者在引导公众消费邮政、以普遍服务取得政府专业性补贴、赢得公众满意度提高等方面所做的努力。邮政企业满足这些外部利益相关者需求的同时自然形成对企业绩效的肯定;根据市场的选择和经营者的决策来制订业绩衡量指标,并纳入整个绩效评价体系,也就成为对邮政企业评价中相当重要的内容。
3、邮政企业属中央国有,国有资本盈余水平自然成为评定经营者业绩的根本标准之一。前文提及的非财务因素、未来绩效驱动因素以及外部利益相关因素都是围绕国有资本盈余为目标的。邮政企业“三年扭亏、扭亏才能保值、保值才能增值”,应是顺理成章的道理,实际上这种认识只能表明国有资本存在的现象,其潜在的盈余能力被忽视了。传统财务指标体系对资产质量(资本存在形式)的分析只是停在会计信息基础上,如资产利润率、资产负债率等,而资产管理指标如产权比例、资产周转程度、实际运作质量、保值比率以及市场经营份额等情况却未得到体现,企业资本存在的市场风险也得不到必要的揭示,资本潜在盈余能力被忽视掉。潜在能力代表国有资本运作方向及企业未来价值,它是在现象中加入时间因素来考虑的,它可以把企业现时损亏看成是现象损亏与未来盈余的综合。虽然资本分配形式与资产运作质量有着密切关系,但如何有效地利用资本结构,充分发挥其未来盈余能力,在信息经济快速发展的今天,也就成为国有邮政企业研究未来如何发展的重要问题之一。市场经济使国有邮政企业将经营方向转向以资本为主,改变现时单一资本结构,使其由多层化向多级化发展便成为提高国有邮政企业资本运作质量的有益思路之一。这种以资本潜在盈余能力为主要体系的发展指标,自然应在评价邮政企业绩效指标中占主导地位。
相关文章
- 详细阅读
- 详细阅读
-
Java的就业前景是怎么样啊?详细阅读

Java的就业前景怎么样?带大家了解一下Java真实的就业前景! 1、Java程序员市场需求缺口大 近年中国在移动互联网这块发展非常迅猛,各种创业公司、小团队如雨后春笋般冒出来,对安
-
为什么出现java.security.spec.Inv详细阅读

RAS签名报错 java.security.InvalidKeyException: IOException : Detect premature EOF,是什么原因你的私钥是代码生成的吗?不能随便写,另外再看一下私钥的长度。
简介:RAS顾名 -
Java(数据结构)利用随机函数产生3000详细阅读

利用随机函数产生30000个随机整数,利用插入排序,起泡排序,选择排序,快速排序,#define _CRT_SECURE_NO_WARNINGS #include #include #include void maopao(int *a, int n) //
-
hmcl加mod后非正常退出,且已有JAVA详细阅读
hmcl非正常退出怎么回事? 有的朋友遇到了hmcl启动器游戏非正常退出这种情况,该怎么办呢?下面小编就为大家带来了hmcl启动器游戏非正常退出的解决办法,希望可以帮助到大家哦。
-
金蝶录入凭证提示:从voucher.ocx加载详细阅读
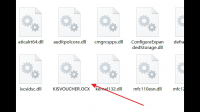
我在用金蝶专业版的凭证录入模块时出现从KISVOUCHER.OCX加载控件VOUCHERVIEW失败。请问这个要怎么处理啊缺失KISVOUCHER.OCX文件的问题,修复步骤如下:1、首先,在一定途径获取KI
-
请问我的世界1.19.2java服务器Sign详细阅读

我的世界java如何安装插件?1.首先打开我的世界,在组件中心切换到功能组件栏目,在功能组件栏目可以根据游戏版本来浏览插件。 2.鼠标放在图标上会显示版本和作者信息,点击图片会
-
这种配置可以玩什么样的Minecarft详细阅读

求介绍适配minecarft光影水反等高配材质的最佳电脑配置 价格适中的显示器的屏幕材质建议使用IPS硬屏或MVA面板的,画面更绚丽,颜色失真更少,可视角度更广。还有那个三星PLS面板
-
我的世界官网美服java版启动器下不详细阅读

为什么我的世界java下载不了?解决办法如下:JAVA不能用MCPACK格式,只支持ZIP,可能会导致资源包出现问题。JAVA不能用manifest,如果是这个原因只能换一个版本进行下载。版本不对,写