
电脑突然蓝屏,然后重启变成图上这样一直进不去系统,bios系统设置过最后的英文提示“DISK BOOT FAILURE,INSERT SYSTEM DISK AND PRESS ENTER ”的意思: 磁盘引导失败,插入系统
我这里有一些数据,不知道用什么方法建模好
软件
2023-08-27
在做数学建模题时,都有那些方法可以处理大量数据
结合数模培训和参赛的经验,可采用数据挖掘中的多元回归分析,主成分分析、人工神经网络等方法在建模中的一些成功应用。以全国大学生数学建模竞赛题为例,数据处理软件Excel、Spss、Matlab在数学建模中的应用及其重要性。
当需要从定量的角度分析和研究一个实际问题时,人们就要在深入调查研究、了解对象信息、作出简化假设、分析内在规律等工作的基础上,用数学的符号和语言作表述来建立数学模型。
数学建模一般应用于高新技术领域和工程领域,对于寻常生活来说,并无很大的应用。而学生参与数学建模的学习和竞赛主要是培养学生的数学思维、创新思维、逻辑思维、团队协作能力和论文写作技巧等。此外,若能在数学建模中获奖,有利于本科、研究生等的学校申请。
数学建模的一般过程:模型准备、模型假设、模型建立、模型求解、模型分析、模型检验。
数学建模是一种数学的思考方法,是运用数学的语言和方法,把错综复杂的实际问题简化、抽象为合理的数学结构,建立起反映实际问题的数量关系,然后利用数学的理论和方法去分析和解决问题。数学建模是数学来源于生活而有应用与生活的桥梁和纽带。
数学建模的方法有哪些?
预测模块:灰色预测、时间序列预测、神经网络预测、曲线拟合(线性回归);
归类判别:欧氏距离判别、fisher判别等 ;
图论:最短路径求法 ;
最优化:列方程组 用lindo 或 lingo软件解 ;
其他方法:层次分析法 马尔可夫链 主成分析法 等 。
建模常用算法,仅供参考:
蒙特卡罗算法(该算法又称随机性模拟算法,是通过计算机仿真来解决 问题的算法,同时间=可以通过模拟可以来检验自己模型的正确性,是比赛时必 用的方法) 。
数据拟合、参数估计、插值等数据处理算法(比赛中通常会遇到大量的数 据需要处理,而处理数据的关键就在于这些算法,通常使用Matlab 作为工具) 。
线性规划、整数规划、多元规划、二次规划等规划类问题(建模竞赛大多 数问题属于最优化问题,很多时候这些问题可以用数学规划算法来描述,通 常使用Lindo、Lingo 软件实现) 。
图论算法(这类算法可以分为很多种,包括最短路、网络流、二分图等算 法,涉及到图论的问题可以用这些方法解决,需要认真准备) 。
动态规划、回溯搜索、分治算法、分支定界等计算机算法(这些算法是算 法设计中比较常用的方法,很多场合可以用到竞赛中) 。
最优化理论的三大非经典算法:模拟退火法、神经网络、遗传算法(这些 问题是用来解决一些较困难的最优化问题的算法,对于有些问题非常有帮助, 但是算法的实现比较困难,需慎重使用) 。
网格算法和穷举法(网格算法和穷举法都是暴力搜索最优点的算法,在很 多竞赛题中有应用,当重点讨论模型本身而轻视算法的时候,可以使用这种 暴力方案,最好使用一些高级语言作为编程工具) 。
一些连续离散化方法(很多问题都是实际来的,数据可以是连续的,而计 算机只认的是离散的数据,因此将其离散化后进行差分代替微分、求和代替 积分等思想是非常重要的) 。
数值分析算法(如果在比赛中采用高级语言进行编程的话,那一些数值分 析中常用的算法比如方程组求解、矩阵运算、函数积分等算法就需要额外编 写库函数进行调用) 。
图象处理算法(赛题中有一类问题与图形有关,即使与图形无关,论文 中也应该要不乏图片的,这些图形如何展示以及如何处理就是需要解决的问 题,通常使用Matlab 进行处理)。
常用的输入数据建模方法有哪些?他们的应用特点是什么?
目前最常用的三种数据模型为层次模型、网状模型和关系模型。 一、层次模型 层次模型将数据组织成一对多关系的结构,层次结构采用关键字来访问其中每一层次的每一部分。 层次模型发展最早,它以树结构为基本结构,典型代表是IMS模型。 优点是存取方便且速度快;结构清晰,容易理解;数据修改和数据库扩展容易实现;检索关键属性十分方便。 二、网状模型 网状模型用连接指令或指针来确定数据间的显式连接关系,是具有多对多类型的数据组织方式。 网状数据模型通过网状结构表示数据间联系,开发较早且有一定优点,目前使用仍较多,典型代表是 DBTG模型。 优点是能明确而方便地表示数据间的复杂关系。数学建模的方法有哪些?
这是网上copy来的,写得还不错: 要重点突破: 1 预测模块:灰色预测、时间序列预测、神经网络预测、曲线拟合(线性回归); 2 归类判别:欧氏距离判别、fisher判别等 ; 3 图论:最短路径求法 ; 4 最优化:列方程组 用lindo 或 lingo软件解 ; 5 其他方法:层次分析法 马尔可夫链 主成分析法 等 ; 6 用到软件:matlab lindo (lingo) excel ; 7 比赛前写几篇数模论文。 这是每年参赛的赛提以及获奖作品的解法,你自己估量着吧…… 赛题 解法 93A非线性交调的频率设计 拟合、规划 93B足球队排名 图论、层次分析、整数规划 94A逢山开路 图论数据建模的如何进行
概念建模
数据建模大致分为三个阶段,概念建模阶段,逻辑建模阶段和物理建模阶段。其中概念建模和逻辑建模阶段与数据库厂商毫无关系,换言之,与MySQL,SQL Server,Oracle没有关系。物理建模阶段和数据库厂商存在很大的联系,因为不同厂商对同一功能的支持方式不同,如高可用性,读写分离,甚至是索引,分区等。
概念建模阶段
实际工作中,在概念建模阶段,主要做三件事:
1. 客户交流
2. 理解需求
3. 形成实体
这也是一个迭代,如果先有需求,尽量去理解需求,明白当前项目或者软件需要完成什么,不明白或者不确定的地方和客户及时交流,和客户double confirm过的需求,落实到实体(Package);但是好多时候我们需要通过先和客户交流,进而将交流结果落实到需求,之后进一步具体到实体;本文可能会涉及到一些来自于EA(Enterprise Architect 7.1)建模术语,(EA中将每个实体视为一个Package)。这里并不对各种建模工具进行比较,如Visio,EA,PowerDesigner, ERWin等;其实作为员工的我们选择性很少,公司有哪个产品的Licence,我们就用哪个吧。
举例说明:在一个B2C电子商务网站中,这样的需求再普通不过了:客户可以在该网站上自由进行购物!我们就以这个简单例子,对其进行细分,来讲解整个数据建模的过程,通过上面这句话,我们可以得出三个实体:客户,网站,商品;就像Scrum(敏捷开发框架的一种)中倡导的一样每个Sprint,都要产出确确实实的东西,OK,概念建模阶段,我们就要产出实体。客户和商品(我们将网站这个实体扔掉,不需要它。)
在创建这两个实体(Package)的时候,我们记得要讲对需求的理解,以及业务规则,作为Notes添加到Package中,这些信息将来会成为数据字典中非常重要的一部分,也就是所谓的元数据。BTW,EA或者其他建模工具应该都可以自动生成数据字典,只不过最终生成的格式可能不太一样。如在Customer这个Package的Notes上,我们可以这样写,用户都要通过填写个人基本信息以及一个邮箱来注册账户,之后使用这个邮箱作为登录帐号登录系统进行交易。
在概念建模阶段,我们只需要关注实体即可,不用关注任何实现细节。很多人都希望在这个阶段把具体表结构,索引,约束,甚至是存储过程都想好,没必要!!因为这些东西使我们在物理建模阶段需要考虑的东西,这个时候考虑还为时尚早。可能有的人在这个阶段担心会不会丢掉或者漏掉一些实体?也不用担心,2013年好多公司都在采用Scrum的开发模式,只要你当前抽象出来的实体满足当前的User Story,或者当前的User Story里面的实体,你都抽象出来了,就可以了!如果你再说,我们User Story太大,实体太多,不容易抽象,那就真没办法了,建议你们的团队重新开Sprint 计划会议。
逻辑建模
逻辑建模阶段
对实体进行细化,细化成具体的表,同时丰富表结构。这个阶段的产物是,可以在数据库中生成的具体表及其他数据库对象(包括,主键,外键,属性列,索引,约束甚至是视图以及存储过程)。我在实际项目中,除了主外键之外,其他的数据库对象我都实在物理建模阶段建立,因为其他数据库对象更贴近于开发,需要结合开发一起进行。如约束,我们可以在web page上做JavaScript约束,也可以在业务逻辑层做,也可以在数据库中做,在哪里做,要结合实际需求,性能以及安全性而定。
针对Customer这个实体以及我们对需求的理解,我们可以得出以下几个表的结构,用户基本信息表(User),登录账户表(Account),评论表(Commnets,用户可能会对产品进行评价),当然这个案例中我们还会有更多的表,如用户需要自己上传头像(图片),我们要有Picture表。
针对产品实体,我们需要构建产品基本信息表(Product),通常情况下,我们产品会有自己的产品大类(ProductCategory)甚至产品小类(ProductSubCategory),某些产品会因为节假日等原因进行打折,因为为了得到更好的Performance我们会创建相应ProductDiscount表,一个产品会有多张图片,因此产品图片表(ProductPicture)以及产品图片关系表(ProductPictureRelationship),(当然我们也可以只设计一张Picture表,用来存放所有图片,用户,产品以及其他)有人说产品和图片是一对多的关系,不需要创建一个关系表啊?是的,我认为只要不是一对一的关系,我都希望创建一个关系表来关联两个实体。这样带来的好处,一是可读性更好,实现了实体和表一一对应的关系,二是易于维护,我们只需要维护一个关系表即可,只有两列(ProductID和PictureID),而不是去维护一个Picture表。
客户进行交易,即要和商品发生关系,我们需要Transaction表,一个客户会买一个或者多个商品,因为一笔Transaction会涉及一个或多个Products,因此一个Transaction和ProductDiscount之间的关系(ProductDiscount和Product是一一对应的关系)需要创建,我们称其为Item表,里面保存TransactionID以及这笔涉及到的ProductDiscountID(s),这里插一句,好多系统都需要有审计功能,如某个产品历年来的打折情况以及与之对应的销售情况,我们这里暂不考虑审计方面的东西。
就这样,我们根据需求我们确定下来具体需要哪些表,进一步丰富每一个表属性(Column),当然这里面会涉及主键的选取,或者是使用代理键(Surrogate Key),外键的关联,约束的设置等细节,这里笔者认为只要能把每个实体属性(Column)落实下来就是很不错了,因为随着项目的开展,很多表的Column都会有相应的改动。至于其他细节,不同数据库厂商,具体实现细节不尽相同。关于主键的选取多说一句,有的人喜欢所有的表都用自增长ID作为主键,而有的人希望找到唯一能标识当前记录的一个属性或者多个属性作为主键;自增长ID作为代理主键,对于将来以多个类似当前Transaction System作为数据源,构建数据仓库的时候,这些自增长ID主键会是一个麻烦(多个系统中,相同表存在大量主键重复);使用一个属性或多个属性作为作为主键,不管主键是可编辑的,读写效率是我们必须考虑得。所以并没有一个放之四海而皆准的原则,笔者只是给大家推荐一些考虑的因素。
物理建模
物理建模阶段
EA可以将在逻辑建模阶段创建的各种数据库对象生成为相应的SQL代码,运行来创建相应具体数据库对象(大多数建模工具都可以自动生成DDL SQL代码)。但是这个阶段我们不仅仅创建数据库对象,针对业务需求,我们也可能做如数据拆分(水平或垂直拆分),如B2B网站,我们可以将商家和一般用户放在同一张表中,但是针对PERFORMANCE考虑,我们可以将其分为两张表;随业务量的上升,Transaction表越来越大,整个系统越来越慢,这个时候我们可以考虑数据拆分,甚至是读写分离(即实现MASTER-SLAVE模式,MYSQL/SQLSERVER可以使用Replication,当然不同存储引擎采用不同的方案),这个阶段也会涉及到集群的事情,如果你是架构师或者数据建模师,这个时候你可以跟DBA说,Alright,I am done with it,now is your show time.
相信大家都知道范式,更有好多人把3NF奉为经典,3NF确实很好,但是3NF是几十年前提出来的,那个时候的数据量以及访问频率和2012年完全不是一个数量级的;因此我们绝对不能一味地遵守3NF;在整个数据建模过程中,在保证数据结构清晰的前提下,尽量提高性能才是我们关注的要点,因此笔者大力倡导数据适当冗余!
上面笔者是结合一些实际例子表达自己对数据建模的观点,希望对读着有用。在数据建模过程中,不要希望一步到位将数据库设计完整,笔者不管是针对data warehouse还是Transactional Database设计,从来没有过一次成功的经历。随着项目的进行,客户和开发团队对业务知识与日增长,因此原来的设计也在不断完善中。毕竟,数据建模或者设计数据库不是我们的最终目的,我们需要的是一个健壮,性能优越,易扩展,易使用的软件!
相关文章
- 详细阅读
-
我用360安全卫士清理电脑并杀毒后,详细阅读
我用360安全卫士清理系统垃圾时,E盘上的文件全部丢失下载数据恢复软件吧,不过在数据恢复出来之前,不要再对E盘进行读写操作了。我空间里有一款极好的数据恢复软件,可以把你的数
- 详细阅读
-
Excel里输入两列数据,呈对应关系,任详细阅读
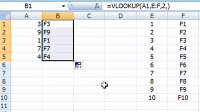
怎样在excel单元格中输入一个数据,自动出现对应的数据见截图一般情况要有个对照表,两组数据一一对应,比如EF列为数据源A列输入数据的(E列的),根据A列输入,B列出现与E列对应F列的数
-
在java的service方法里怎么才算是详细阅读
在java的service方法里怎么才算是一个数据库会话?和事务关系是什么?是的,ServiceA.methodA() 方法是 使用了@Transactional 注解,会开启事务,当调用serviceB.methodB();方法的时
-
xpath要怎么得到下等式后面的数据详细阅读
Python怎样获取XPath下的A标签的内容1、在浏览器中打开网页。然后//div,就可以找到页面中的所有div了,因为//表示的是任意目录下查找。如图,页面有两个div,所以可以找到两个。2
-
access中创建一个数据库为"XXX学生详细阅读
用ACCESS创建一个本班级学生考试成绩管理系统怎么创建?要一个.mdb文件就行。你自己不是说的很清楚了吗,表名:成绩表 字段名字 数据类型 学号 NUM 姓名 CHAR 语文 double 同上
-
昨天查的护照还在制作中,今天在查就详细阅读

查询护照办理进度为什么显示查无数据呢护照的办理时限15个工作日,只能通过当地公安机关营业厅办理,并不能通过网上查询办理进度。可以通过本人的护照办理上面电话查询。
护照 -
苹果13配条拆机数据线数据线写着in详细阅读

iPhone的数据线序列号怎么查询?距离USB插头20厘米左右处有字Designed by Apple in California Assembled in China 序列号(中国产)Designed by Apple in California Assemble
-
我已经有文件加密系统了,还需要采购详细阅读

我已经有文件加密系统了,还需要采购数据库加密系统么?需要,常规的文件加密系统都表现为工具程序,一般只能对指定的文件进行加密保护,对于不同的文件可以分别设置不同的访问口令/