
大数据云计算好不好学习?你好,很高兴为你解答: 大数据和云计算其实并不难学,学习云计算及大数据需要有java,linux,mysql、python等基础,一般4到5个月的培训就能找工作了。 云计算的
ETLCloud包含哪些模块?
软件
2023-07-25
什么是ETL?
Extraction-Transformation-Loading的缩写,中文名称为数据提取、转换和加载。 ETL工具有:OWB(Oracle Warehouse Builder)、ODI(Oracle Data Integrator)、Informatic PowerCenter、Trinity、AICloudETL、DataStage、Repository Explorer、Beeload、Kettle、DataSpider 目前,ETL工具的典型代表有:Informatica、Datastage、OWB、微软DTS、Beeload、Kettle…… 开源的工具有eclipse的etl插件简述云服务高可用架构的组成包含哪些模块?并简要说明各模块的作用
云服务的高可用性 (HA) 体系结构通常包括以下组件:
负载均衡器:这些负载均衡器在多个服务器或实例之间分配传入流量,以确保工作负载均衡,并且即使一个或多个服务器发生故障,服务也保持可用。
容错存储:这可确保以冗余且高可用性的方式存储数据,以便即使一个或多个存储节点发生故障也可以访问数据。这可能包括数据复制、快照和灾难恢复等功能。
灾难恢复解决方案:这些解决方案提供了从重大中断或灾难(例如整个数据中心丢失)中恢复的机制。这可能包括备份和还原功能,以及在发生灾难性事件时故障转移到辅助站点或区域的能力。
监视和警报:这有助于检测服务问题并通知相应的团队,以便他们可以采取措施解决问题。这可能包括实时监控关键指标和日志,以及自动警报和通知。
这些组件中的每一个在确保云服务的可用性和可靠性方面都起着关键作用。负载均衡器分配传入流量,并确保即使某些服务器发生故障,服务也保持可用。容错存储可确保数据受到保护,即使某些存储节点发生故障也可以访问。灾难恢复解决方案提供了从重大中断或灾难中恢复的机制。监控和警报系统有助于检测和响应服务问题。这些组件共同构成了云服务高可用性体系结构的核心。
回答不易望请采纳
ETL工具主流产品有哪些?
几种ETL工具的比较(DataPipeline,Kettle,Talend,Informatica等)
四种工具的比较主要从以下几方面进行比对:
1、成本:
软件成本包括多方面,主要包括软件产品,售前培训,售后咨询,技术支持等。
开源产品本身是免费的,成本主要是培训和咨询,所以成本会一直维持在一个较低水平。
商业产品本身价格很高,但是一般会提供几次免费的咨询或支持,所以采用商用软件最初成本很高,但是逐渐下降。
手工编码最初成本不高,主要是人力成本,但后期维护的工作量会越来越大。
2、易用性:
DataPipeline:有非常容易使用的GUI,具有丰富的可视化监控;
Kettle:GUI+Coding;
Informatica:GUI+Coding,有GUI,但是要专门的训练;
Talend:GUI+Coding,有GUI图形界面但是以Eclipse的插件方式提供;
3、技能要求:
DataPipeline:操作简单,无技术要求;
Kettle:ETL设计,SQL,数据建模;
Informatica:ETL设计,SQL,数据建模;
Talend:需要写Java;
4、底层架构:
DataPipeline:分布式,可水平扩展;
Kettle:主从结构非高可用;
Informatica:分布式;
Talend:分布式;
5、数据实时性:
DataPipeline:支持异构数据源的实时同步,速度非常快;
Kettle:不支持实时数据同步;
Informatica:支持实时,效率较低;
Talend:支持实时处理,需要购买高级版本,价格贵;
6、技术支持:
DataPipeline:本地化原厂技术支持;
Kettle:无;
Informatica:主要在美国;
Talend:主要在美国;
7、自动断点续传:
DataPipeline:支持;
Kettle:不支持;
Informatica:不支持;
Talend:不支持;
etl是什么
对于做过 BI 开发的朋友,ETL 并不陌生,只要涉及到数据源的数据抽取、数据的计算和处理过程的开发,都是 ETL,ETL 就这三个阶段,Extraction 抽取,Transformation 转换,Loading 加载。
从不同数据源抽取数据 EXTRACTION ,按照一定的数据处理规则对数据进行加工和格式转换 TRASFORMATION,最后处理完成的输出到目标数据表中也有可能是文件等等,这个就是 LOADING。
再通俗一点讲,ETL 的过程就跟大家日常做菜一样,需要到菜市场的各个摊位买好菜,把菜买回来要摘一下,洗一洗,切一切最后下锅把菜炒好端到饭桌上。菜市场的各个摊位就是数据源,做好的菜就是最终的输出结果,中间的所有过程像摘菜、洗菜、切菜、做菜就是转换。
在开发的时候,大部分时候会通过 ETL 工具去实现,比如常用的像 KETTLE、PENTAHO、IBM DATASTAGE、INFORNAICA、微软 SQL SERVER 里面的 SSIS 等等,在结合基本的 SQL 来实现整个 ETL 过程。
也有的是自己通过程序开发,然后控制一些数据处理脚本跑批,基本上就是程序加 SQL 实现。
哪种方式更好,也是需要看使用场景和开发人员对那种方式使用的更加得心应手。我看大部分软件程序开发人员出身的,碰到数据类项目会比较喜欢用程序控制跑批,这是程序思维的自然延续。纯 BI 开发人员大部分自然就选择成熟的 ETL 工具来开发,当然也有一上来就写程序脚本的,这类 BI 开发人员的师傅基本上是程序人员转过来的。
用程序的好处就是适配性强,可扩展性强,可以集成或拆解到到任何的程序处理过程中,有的时候使用程序开发效率更高。难就难在对维护人员有一定的技术要求,经验转移和可复制性不够。

用 ETL 工具的好处,第一是整个 ETL 的开发过程可视化了,特别是在数据处理流程的分层设计中可以很清晰的管理。第二是链接到不同数据源的时候,各种数据源、数据库的链接协议已经内置了,直接配置就可以,不需要再去写程序去实现。第三是各种转换控件基本上拖拉拽就可以使用,起到简化的代替一部分 SQL 的开发,不需要写代码去实现。第四是可以非常灵活的设计各种 ETL 调度规则,高度配置化,这个也不需要写代码实现。
所以在大多数通用的项目中,在项目上使用 ETL 标准组件开发会比较多一些。
ETL 从逻辑上一般可以分为两层,控制流和数据流,这也是很多 ETL 工具设计的理念,不同的 ETL 工具可能叫法不同。
控制流就是控制每一个数据流与数据流处理的先后流程,一个控制流可以包含多个数据流。比如在数据仓库开发过程中,第一层的处理是ODS层或者Staging 层的开发,第二层是 DIMENSION维度层的开发,后面几层就是DW 事实层、DM数据集市层的开发。通过ETL的调度管理就可以让这几层串联起来形成一个完整的数据处理流程。
数据流就是具体的从源数据到目标数据表的数据转换过程,所以也有 ETL 工具把数据流叫做转换。在数据流的开发设计过程中主要就是三个环节,目标数据表的链接,这两个直接通过 ETL 控件配置就可以了。中间转换的环节,这个时候就可能有很多的选择了,调 SQL 语句、存储过程,或者还是使用 ETL 控件来实现。
有的项目上习惯使用 ETL 控件来实现数据流中的转换,也有的项目要求不使用标准的转换组件使用存储过程来调用。也有的是因为数据仓库本身这个数据库不支持存储过程就只能通过标准的SQL来实现。
我们通常讲的BI数据架构师其实指的就是ETL的架构设计,这是整个BI项目中非常核心的一层技术实现,数据处理、数据清洗和建模都是在ETL中去实现。一个好的ETL架构设计可以同时支撑上百个包就是控制流,每一个控制流下可能又有上百个数据流的处理过程。之前写过一篇技术文章,大家可以搜索下关键字 BIWORK ETL 应该在网上还能找到到这篇文章。这种框架设计不仅仅是ETL框架架构上的设计,还有很深的ETL项目管理和规范性控制器思想,包括后期的运维,基于BI的BI分析,ETL的性能调优都会在这些框架中得到体现。因为大的BI项目可能同时需要几十人来开发ETL,框架的顶层设计就很重要。
eTraining平台包含哪几个模块,其中训练管理模块包含哪些内容?
eTraining平台包含企业和HR人员对培训的资源、流程和绩效进行管理的,其中训练管理模块包含外派人员培训、外请讲师内训和内部讲师内训,还包括工作中的培训(OJT-onjob training)、员工自学和eLearning培训等所有形式的培。
募随eTraining(在线培训考核系统)基于网络的在线培训和评估系统,充分实现了e-learning的设计理念,为现代学习型组织提供了卓有成效的学习和培训方案,通过在线学习、在线考试和在线评估轻松完成了为员工制定的培训方案。
满足企业教学培训管理、组织考试、成绩统计、绩效考核等,为领导者对员工素质的公平评价和准确分析提供有力的数据支持。
相关文章
- 详细阅读
-
大数据云计算好不好学习?详细阅读

大数据云计算好不好学习?你好,很高兴为你解答: 大数据和云计算其实并不难学,学习云计算及大数据需要有java,linux,mysql、python等基础,一般4到5个月的培训就能找工作了。 云计算的
-
为什么抖音小店团购只能设置生活服详细阅读

抖音小店本地服务类商品订单不支持加购物车,仅支持立即购买对吗?一、抖音PC端商家后台核销 第一步:用抖音账号登录商家后台,点【订单】-【核销管理】功能模块,可以直接对订单进
-
云计算技术与应用专业现在算不算大详细阅读

云计算应用技术这个专业好不好?就业呢?这个专业可以根据高职高专学生特色注重培养学生较强实践动手能力,面向云计算大数据时代IT行业公司、系统集成商、企业事业单位信息化部门
-
5g大数据云计算物联网人工智能对电详细阅读

5G的到来,会有哪些实质性的改变,对互联网行业会哪些影响?2019年中国5G产业市场分析:开启产业互联网新阶段,全球化步伐有待加快5G板块热度不减 开启产业互联网新阶段近期,5G板块热
-
别人热爱生活的态度确实值得我学习详细阅读

怎么控制自己的负能量情绪呢?转移自己的注意力。我们不可能将自己产生的情绪重新变没,只能通过自己的转移,去想办法转移自己的注意力,让自己的注意力不要再那间糟糕的事情上,将自
-
大神您好!感谢上次您的帮助。又遇详细阅读

您好,首先感谢您以前的对我的帮助,祝新年快乐!其次,我又遇到问题了,希望大神教我。建议用SQL选择查询根据“缓解度”算出“疗效”,而不需要实际存储维护这个疗效字段。例如 select
-
健康生活为主题的电脑动画flash详细阅读
求(必须)自创的一份关于低碳生活的flash动画--各位电脑爱好者帮帮忙很简单,只要搜索一些关于低碳生活的资料,领悟其中的意思,然后根据自己领悟到的写一下就好了。求全国“健康教
-
3、你能找出生活中存在反比例函数详细阅读
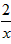
生活中具有反比例函数关系的实例1.路程一定时,汽车的速度和时间成反比例. 2.长方形面积一定时,长与宽成反比例. 3.总价一定时,单价与数量成反比例.举出一个生活中能用反比例
-
我的世界新生活大冒险整合包(10.1版详细阅读
我的世界生活大冒险整合包怎么下载我知道,下载一个快吧游戏,然后用快吧下载就可以了,这里还包括怪物大乱斗等我的世界生活大冒险组合包在哪里下载?很高兴为您解答以下是生活大冒