图中的软件是什么?“FL Studio”,常被人们称为“苹果机”,用来编辑音乐用的,例如加鼓点、军鼓、锣声等。这个图片里的是什么软件Illustrator或用CorelDRAW可以制作出这种效果。
SPSS对年龄、家庭规模重新编码为不同变量时,旧值和新值出现重合,怎么办
软件
2023-05-18
spss怎么进行重新编码不同变量
重新编码为不同变量,是根据原来变量,某一值或某一值范围,变成一个新的数值,如,原来是原始的年龄,可以重新编码为年龄段;或者原来是原始考试分数,可以重新编码为等级。 计算变量则是在原来某一或某些变量上做一些计算,变成新变量的过程。如可以把原始分数统一加一个分数,也可以把各科分数求总和,也可以做其他运算。怎样在spss中将数值型变量转换成分类变量,比如将年龄转换成年龄段,并记为1,2,3等类
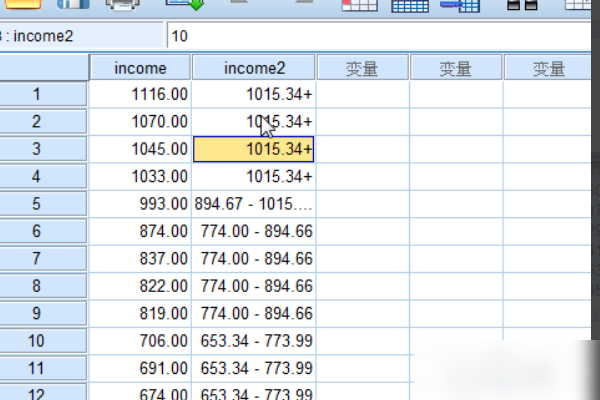
1、打开spss,这里的第一列是可变收入,我们用这个scale变量作为例子来生成一个新的分类变量income2。
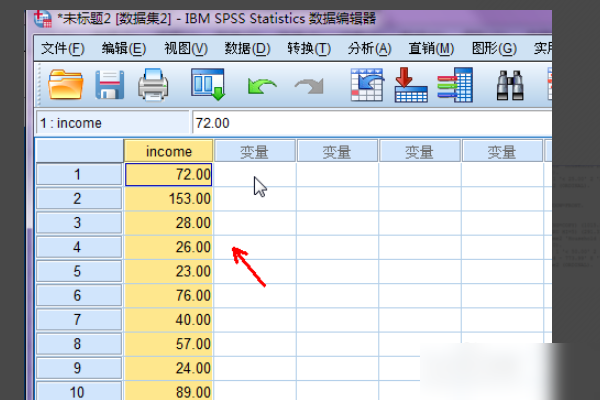
2、单击菜单栏中的转换,选择下拉列表中的数据进行离散化。
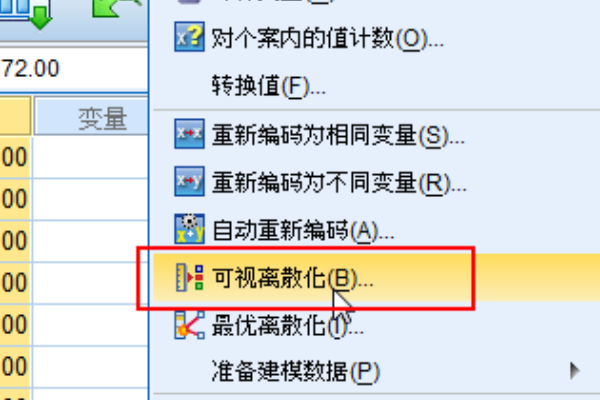
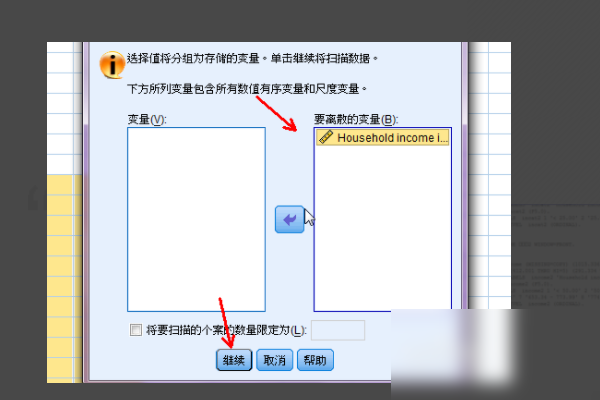
3、出现一个对话框。由于我们只有收入变量且仅对此变量进行分类,因此选择它,单击箭头,然后移动到变量框以使其成为离散变量。
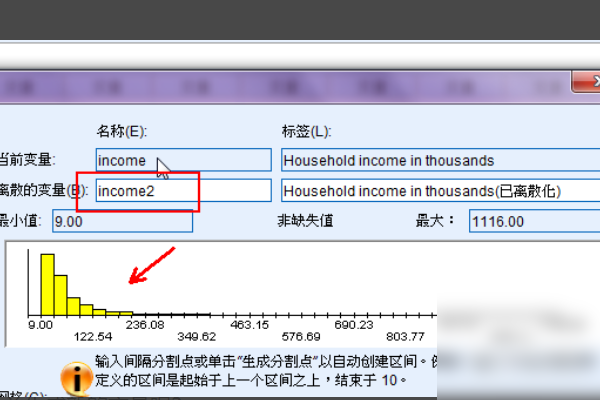
4、在对话框的离散变量后面的框中输入新变量名称。这里我们输入income2,它是生成的分类变量的名称。您可以看到图中所有数据的分布。
5、单击对话框右下角的分割点,我们将开始对数据进行分类。
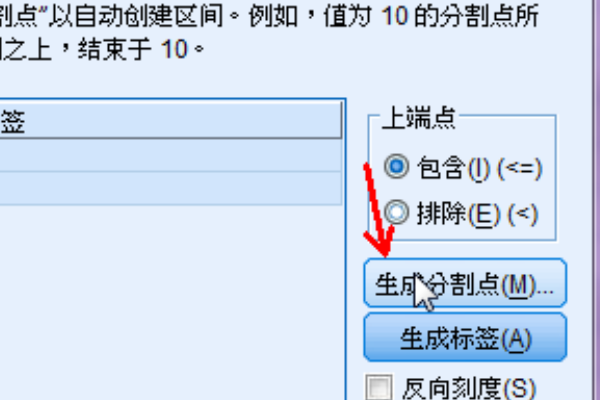
6、在第一个分割点的位置输入50。分割点的数量设置为9.实际上,数据将分为10组。宽度软件将自动计算并生成。单击该应用程序。点和数量根据需要确定。
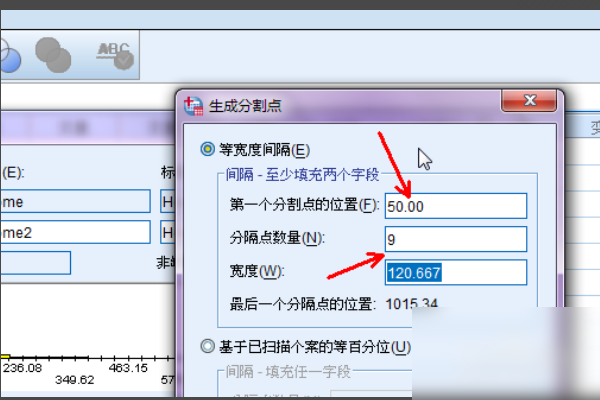
7、刚刚返回对话框时,出现了一些很好的数据分割点。单击右侧的排除项。通常,我们都包括下限而不是上限。
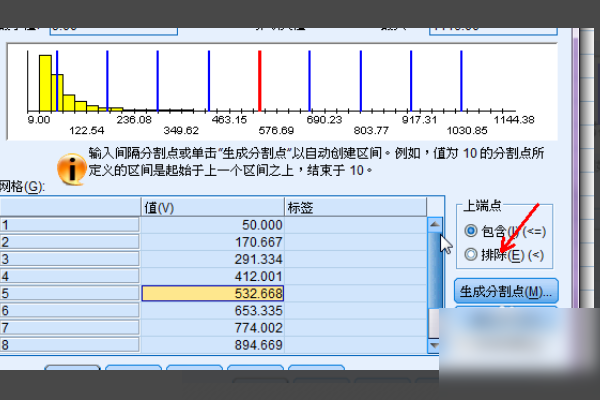
8、单击“排除”,然后单击“生成标记”以查看该组生成的标记,即一系列数据点。
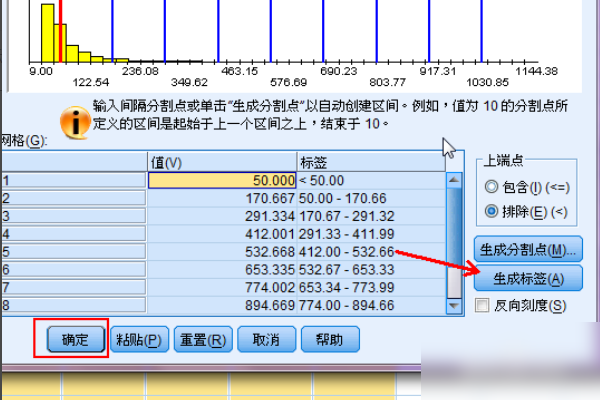
9、单击“确定”,弹出一个对话框,仍然单击“确定”,您可以看到新生成的变量income2。
紧急求助:用SPSS分析某疾病在不同年龄组中患病率的差别有无统计学意义(在线等结果)谢谢
做卡方检验,先设置三个变量:
年龄、患者、百分比,然后将百分比加权(菜单栏点击数据——加权),再点击菜单栏分析——描述分析——交叉分析(或列联表分析),在统计值中选择卡方值就可以了。最后看卡方值对应的sig值是否小于0.05,如果是,说明有显著差异。
p值小于0.05或者小于0.05,都说明了要分析的两分类变量之间是有显著的相关的,也就是说不通年龄段的患病率有显著的差异。
资料检验
(自由度df=(C-1)(R-1))
行×列表资料的卡方检验用于多个率或多个构成比的比较。
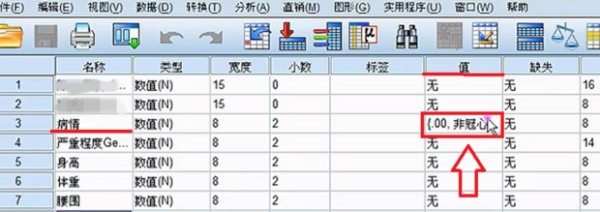
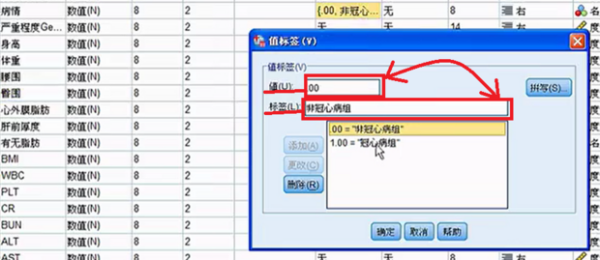
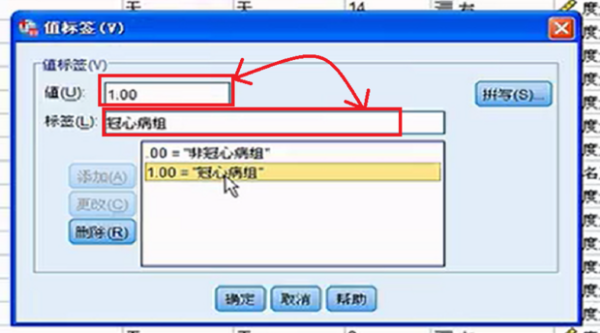
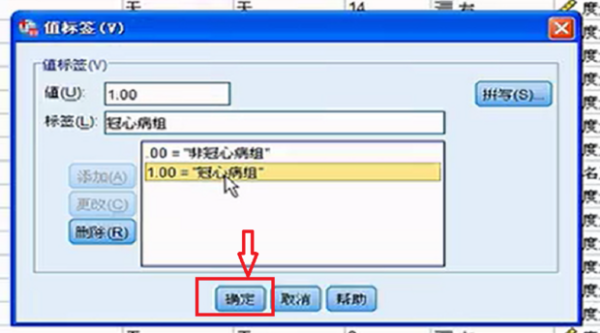
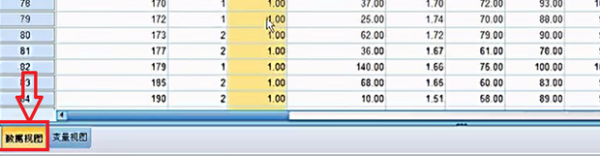
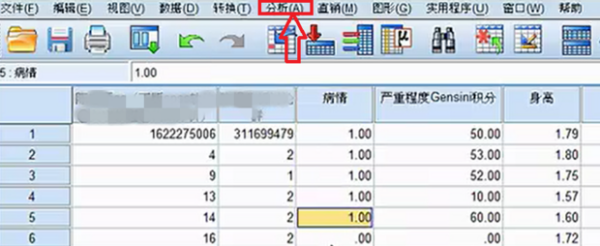
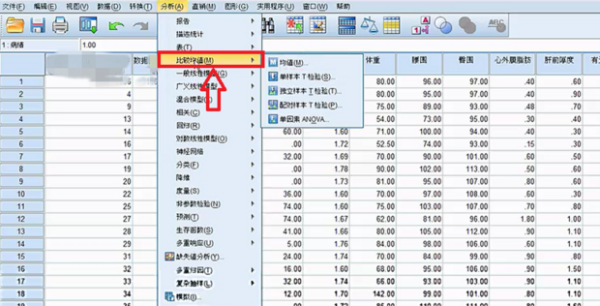
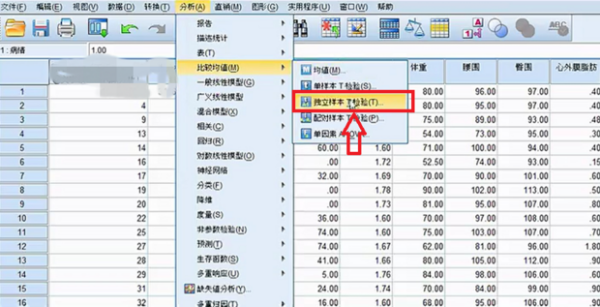
要求每个格子中的理论频数T均大于5或1 以上内容参考:百度百科-卡方检验 选择“转换”菜单下的“重新编码成不同变量(recode into different variable)”,以“总评成绩”为就旧变量(old variable),将其重新编译成新的变量,即可。关于“重新编码“这一命令的操作方式在任何SPSS的书籍中基本都有介绍,在此不再赘述。 注意:在新旧变量转换过程中,在“旧值和新值”对话框中,对于旧值的范围,SPSS是采取两端包含的处理方式,例如,如果你将旧变量“0-60”分编译为新变量的“1”时,那么成绩为0和60的同学也将被编译成1. 1、图示为需要分析的数据。独立样本t检验要求两组样本相对独立。为了方便表示,数据输入时“病情”项的1和0分别代表患病与不患病,这里患病与不患病就构成了两组独立数据。可用SPSS分析冠心病的发病是否与身高、体重、臀围等因素有关系。 2、单击数据窗口左下侧的“变量视图“,在里面可以设置变量的分析比较相关 3、选择“病情”横排中,“值”一列的单元格单击。 4、在弹出的“值标签”窗口中,你需要设置值和标签相对应,“值”就是指刚才的1和0,这里就是把1和0与患冠心病和不患冠心病相对应。在“值”的00对应的“标签”输入框中输入“非冠心病组”。 5、在“值”的1.00对应的“标签”输入框中输入“冠心病组”。 6、单击“确认”保存值标签。 7、在窗口左下方单击“敏感视图”,这就回到了最开始的数据页。 8、单击当下敏感视图窗口工具栏内的“分析”按钮。 9、“分析”按钮的下拉列表中,选择“比较均值”单击。即将两组数据各项的值分别求均值再比较 10、“比较均值”也有下拉列表,单击下拉列表中的“独立样本T检验”即可。 相关文章 蒙泰所有快捷键是那些?MainTop (蒙泰排版软件)快捷键建立新(New)文件 【duCtrl】+【N】打开(Open)编排文件[*.tpf] 【Ctrl】+【O】 哪里可以下载到免费的photoshop下载photoshop有很多广告,一般是下载了捆绑软件,在安装时取消广告软件勾选,即可,具体步骤如下。1、打开电脑浏览器,百度搜索【photoshop下载】找到 手机上有哪些视频特效制作软件?手机上视频特效制作软件推荐:巧影、趣推、神剪手、美摄、小影。1、巧影这款软件超级实用,操作简单,艺术家或教育家们,也可在KineMaster所提供的手 手机收到约炮类短信怎么回事遇到这样的情况,很可能是因为手机的信息、电话号码等这样的被泄露了。 我想 去除视频的背景,但Adobe Ultra 的功能好象不好,输入剪辑 硬性规定只能用一个视频!!Adobe Ultra CS3的矢量色键(Vector Keying)技术是你原有的视频编辑软件上的抠像器无法比拟 微信h5页面如何制作?有没有免费的?有免费的,制作方法如下:登录微传单平台,创建传单。按行业类型选择微传单模板。点击微传单中的文字和图片进行更换、编辑。根据自己的需要添加文 打开PS文件,提示缺少字体该怎么办1、打开链图云字体工具;2、要登录账号才可以使用哦;3、点击“字体助手”导航图标;4、在缺失字体选项栏,点击“字体补齐”;5、可以点击“打开文件 资源多的影视软件资源多的影视软件有:第一款:葫芦视频葫芦视频是当贝与华视网聚合作开发的一款垂直类视频APP,秉承“发现好电影”的品牌内核,专注影视精品化运营,华视网聚提供全spss软件的应用,关于重新赋值。求大神进来看题目
中文版的SPSS 如何把年龄分组,比如1代表18到28的,2代表29到38 的。。依次往下。具体操作步骤 谢谢!
MainTop 蒙泰排版软件
详细阅读

保存文件[*.tpf、*.sty] 【Ctrl】+【S】
PS软件安装包下载
详细阅读
 有没有加特效的软件
详细阅读
有没有加特效的软件
详细阅读
 问一下网上之前收到一个短信是约炮
详细阅读
问一下网上之前收到一个短信是约炮
详细阅读

遇到这样的情况,可以这样做:
1、检查是否开启短信黑名单功能。是否使用第三
各位老师好,Adobe.Ultra.CS3虚拟抠
详细阅读
 微信h5页面免费制作软件怎样下载
详细阅读
打开PS软件,菜单栏上出现小方框,没有
详细阅读
微信h5页面免费制作软件怎样下载
详细阅读
打开PS软件,菜单栏上出现小方框,没有
详细阅读
 有着海量播放资源的软件是哪一款?
详细阅读
有着海量播放资源的软件是哪一款?
详细阅读

