已成功与服务器建立连接,但是在登录前的握手期间发生错误,是怎么回事?确认选择了SQLSERVER和Windows身份验证模式确认may是否设置为允许登录确认may是否有登陆的权限。单击“开
移动云云数据库MySQL是什么?
电脑
2023-11-26
移动云云数据库MySQL是什么?
云数据库MySQL顾名思义就是移动云开发的一款在 线数据库服务,即开即用,数据安全可靠,性能也很好,运维方便!移动云 云数据库MySQL比传统数据库好在哪?
云数据库MySQL比传统数据库,就好在可以节约大量的成本,因为云数据库MySQL不需要额外购置数据库服务器硬件或者软件了;而且使用方法很简单,特别容易上手;此外,采用了SSL、TLS加密技术,实现了传输加密,确保了数据的安全可靠。相比传统自建库,移动云云数据库MySQL的优势是啥?
比其传统自建库,移动云云数据库MySQL优势在于可提供常用数据库及账号的创建与管理,做到事前访问可控,事后操作可追溯,实现日常可视化管理和全面的安全防护;支持根据个人不同使用需求进行弹性扩展,实现弹性的架构设计和便捷的运维管理。 很高兴能为你提供帮助,求给大大的赞。移动云云数据库MySQL可以用在什么行业?
移动云云数据库MySQL能够应用的行业很多,比如医疗医药行业、金融行业,同时电子政务、电子商务等领域也同样试用。什么是MySql数据库
MySQL数据库:
MySQL是一种开放源代码的关系型数据库管理系统(RDBMS),使用最常用的数据库管理语言--结构化查询语言(SQL)进行数据库管理。
MySQL是开放源代码的,因此任何人都可以在General Public License的许可下下载并根据个性化的需要对其进行修改。
MySQL因为其速度、可靠性和适应性而备受关注。大多数人都认为在不需要事务化处理的情况下,MySQL是管理内容最好的选择。
数据库简介:
MySQL是一种开放源代码的关系型数据库管理系统(RDBMS),MySQL数据库系统使用最常用的数据库管理语言--结构化查询语言(SQL)进行数据库管理。
由于MySQL是开放源代码的,因此任何人都可以在General Public License的许可下下载并根据个性化的需要对其进行修改。MySQL因为其速度、可靠性和适应性而备受关注。大多数人都认为在不需要事务化处理的情况下,MySQL是管理内容最好的选择。
MySQL这个名字,起源不是很明确。一个比较有影响的说法是,基本指南和大量的库和工具带有前缀“my”已经有10年以上,而且不管怎样,MySQL AB创始人之一的Monty Widenius的女儿也叫My。这两个到底是哪一个给出了MySQL这个名字至今依然是个迷,包括开发者在内也不知道。
MySQL的海豚标志的名字叫“sakila”,它是由MySQL AB的创始人从用户在“海豚命名”的竞赛中建议的大量的名字表中选出的。获胜的名字是由来自非洲斯威士兰的开源软件开发者Ambrose Twebaze提供。根据Ambrose所说,Sakila来自一种叫SiSwati的斯威士兰方言,也是在Ambrose的家乡乌干达附近的坦桑尼亚的Arusha的一个小镇的名字。
MySQL,虽然功能未必很强大,但因为它的开源、广泛传播,导致很多人都了解到这个数据库。它的历史也富有传奇性。
MySQL数据库历史:
MySQL的历史最早可以追溯到1979年,那时Oracle也才小打小闹,微软的SQL Server影子都没有。有一个人叫Monty Widenius, 为一个叫TcX的小公司打工,并用BASIC设计了一个报表工具,可以在4M主频和16KB内存的计算机上运行。过了不久,又将此工具,使用C语言重写,移植到Unix平台,当时,它只是一个很底层的面向报表的存储引擎。这个工具叫做Unireg。
可是,这个小公司资源有限,Monty天赋极高,面对资源有限的不利条件,他反而更能发挥潜能,总是力图写出最高效的代码。并因此养成了习惯。与Monty同在一起的还有一些别的同事,很少有人能坚持把那些代码持续写到20年后,而Monty却做到了。
1990年,TcX的customer 中开始有人要求要为它的API提供SQL支持,当时,有人想到了直接使用商用数据库算了,但是Monty觉得商用数据库的速度难令人满意。于是,他直接借助于mSQL的代码,将它集成到自己的存储引擎中。但不巧的是,效果并不太好。于是, Monty雄心大起,决心自己重写一个SQL支持。
1996年,MySQL 1.0发布,只面向一小拨人,相当于内部发布。到了96年10月,MySQL 3.11.1发布了,呵呵,没有2.x版本。最开始,只提供了Solaris下的二进制版本。一个月后,Linux版本出现了。
紧接下来的两年里,MySQL依次移植到各个平台下。它发布时,采用的许可策略,有些与众不同:允许免费商用,但是不能将MySQL与自己的产品绑定在一起发布。如果想一起发布,就必须使用特殊许可,意味着要花银子。当然,商业支持也是需要花银子的。其它的,随用户怎么用都可以。这种特殊许可为MySQL带来了一些收入,从而为它的持续发展打下了良好的基础。(细想想,PostgreSQL曾经有几年限入低谷,可能与它的完全免费,不受任何限制有关系)。
MySQL3.22应该是一个标志性的版本,提供了基本的SQL支持。
MySQL关系型数据库于1998年1月发行第一个版本。它使用系统核心提供的多线程机制提供完全的多线程运行模式,提供了面向C、C++、Eiffel、Java、Perl、PHP、Python以及Tcl等编程语言的编程接口(APIs),支持多种字段类型并且提供了完整的操作符支持查询中的SELECT和WHERE操作。
MySQL是开放源代码的,因此任何人都可以在General Public License的许可下下载并根据个性化的需要对其进行修改。MySQL因为其速度、可靠性和适应性而备受关注。
1999-2000年,有一家公司在瑞典成立了,叫MySQL AB (AB是瑞典语“股份公司”的意思)。 雇了几个人,与Sleepycat合作,开发出了 Berkeley DB引擎, 因为BDB支持事务处理,所以,MySQL从此开始支持事务处理了。
2000年4月,MySQL对旧的存储引擎进行了整理,命名为MyISAM。同时,2001年,Heikiki Tuuri向MySQL提出建议,希望能集成他们的存储引擎InnoDB,这个引擎同样支持事务处理,还支持行级锁。
如今,遗憾的是,BDB和InnoDB好像都被Oracle收购了,为了消灭竞争对手,哪怕是开源的,都是不择手段。
MySQL与InnoDB的正式结合版本是4.0。
到了MySQL5.0,2003年12月,开始有View,存储过程之类的东东,当然,其间, bug也挺多。
在2008年1月16号 MySQL被Sun公司收购。
最近,MySQL的创始人Monty Widenius已经向Sun提交了辞呈。head都要走了。
据说,被Sun收购的公司多薄命,不知道MySQL今后前途如何,希望一路走好。相信MySQL的生命力还是很长久的。
时至今日 mysql 和 php 的结合绝对是完美.很多大型的网站也用到mysql数据库.mysql的发展前景是非常光明的!
MySQL常用命令:
1:使用SHOW语句找出在服务器上当前存在什么数据库:
mysql> SHOW DATABASES;
2:2、创建一个数据库MYSQLDATA
mysql> CREATE DATABASE MYSQLDATA;
3:选择你所创建的数据库
mysql> USE MYSQLDATA; (按回车键出现Database changed 时说明操作成功!)
4:查看现在的数据库中存在什么表
mysql> SHOW TABLES;
5:创建一个数据库表
mysql> CREATE TABLE MYTABLE (name VARCHAR(20), sex CHAR(1));
6:显示表的结构:
mysql> DESCRIBE MYTABLE;
7:往表中加入记录
mysql> insert into MYTABLE values (”hyq”,”M”);
8:用文本方式将数据装入数据库表中(例如D:/mysql.txt)
mysql> LOAD DATA LOCAL INFILE “D:/mysql.txt” INTO TABLE MYTABLE;
9:导入.sql文件命令(例如D:/mysql.sql)
mysql>use database;
mysql>source d:/mysql.sql;
10:删除表
mysql>drop TABLE MYTABLE;
11:清空表
mysql>delete from MYTABLE;
12:更新表中数据
mysql>update MYTABLE set sex=”f” where name=’hyq’;
全局管理权限对应解释:
FILE: 在MySQL服务器上读写文件。
PROCESS: 显示或杀死属于其它用户的服务线程。
RELOAD: 重载访问控制表,刷新日志等。
SHUTDOWN: 关闭MySQL服务。
数据库/数据表/数据列权限:
ALTER: 修改已存在的数据表(例如增加/删除列)和索引。
CREATE: 建立新的数据库或数据表。
DELETE: 删除表的记录。
DROP: 删除数据表或数据库。
INDEX: 建立或删除索引。
INSERT: 增加表的记录。
SELECT: 显示/搜索表的记录。
UPDATE: 修改表中已存在的记录。
特别的权限:
ALL: 允许做任何事(和root一样)。
USAGE: 只允许登录–其它什么也不允许做。
MySQL数据库导入方法:
MySQL数据库的导入,有两种方法:
1) 先导出数据库SQL脚本,再导入;
2) 直接拷贝数据库目录和文件。
在不同操作系统或MySQL版本情况下,直接拷贝文件的方法可能会有不兼容的情况发生。
所以一般推荐用SQL脚本形式导入。下面分别介绍两种方法。
2. 方法一 SQL脚本形式
操作步骤如下:
2.1. 导出SQL脚本
在原数据库服务器上,可以用phpMyAdmin工具,或者mysqldump命令行,导出SQL脚本。
2.1.1 用phpMyAdmin工具
导出选项中,选择导出“结构”和“数据”,不要添加“DROP DATABASE”和“DROP TABLE”选项。
选中“另存为文件”选项,如果数据比较多,可以选中“gzipped”选项。
将导出的SQL文件保存下来。
2.1.2 用mysqldump命令行
命令格式
mysqldump -u 用户名 -p 数据库名 > 数据库名.sql
范例:
mysqldump -u root -p abc > abc.sql
(导出数据库abc到abc.sql文件)
提示输入密码时,输入该数据库用户名的密码。
2.2. 创建空的数据库
通过主控界面/控制面板,创建一个数据库。假设数据库名为abc,数据库全权用户为abc_f。
2.3. 将SQL脚本导入执行
同样是两种方法,一种用phpMyAdmin(mysql数据库管理)工具,或者mysql命令行。
2.3.1 用phpMyAdmin工具
从控制面板,选择创建的空数据库,点“管理”,进入管理工具页面。
在"SQL"菜单中,浏览选择刚才导出的SQL文件,点击“执行”以上载并执行。
注意:phpMyAdmin对上载的文件大小有限制,php本身对上载文件大小也有限制,如果原始sql文件
比较大,可以先用gzip对它进行压缩,对于sql文件这样的文本文件,可获得1:5或更高的压缩率。
gzip使用方法:
# gzip xxxxx.sql
得到
xxxxx.sql.gz文件。
提示输入密码时,输入该数据库用户名的密码。
3 直接拷贝
如果数据库比较大,可以考虑用直接拷贝的方法,但不同版本和操作系统之间可能不兼容,要慎用。
3.1 准备原始文件
用tar打包为一个文件
3.2 创建空数据库
3.3 解压
在临时目录中解压,如:
cd /tmp
tar zxf mydb.tar.gz
3.4 拷贝
将解压后的数据库文件拷贝到相关目录
cd mydb/
cp * /var/lib/mysql/mydb/
对于FreeBSD:
cp * /var/db/mysql/mydb/
3.5 权限设置
将拷贝过去的文件的属主改为mysql:mysql,权限改为660
chown mysql:mysql /var/lib/mysql/mydb/*
chmod 660 /var/lib/mysql/mydb/*
Mssql转换mysql的方法:
1.导表结构
使用MySQL生成create脚本的方法。找到生成要导出的脚本,按MySQL的语法修改一下到MySQL数据库中创建该表的列结构什么的。
2.导表数据
在MSSQL端使用bcp导出文本文件:
bcp “Select * FROM dbname.dbo.tablename;” queryout tablename.txt -c -Slocalhost\db2005 -Usa
其中”"中是要导出的sql语句,-c指定使用\t进行字段分隔,使用\n进行记录分隔,-S指定数据库服务器及实例,-U指定用户名,-P指定密码.
在MySQL端使用mysqlimport 导入文本文件到相应表中
mysqlimport -uroot -p databasename /home/test/tablename.txt
其中-u指定用户名,-p指定密码,databasename指定数据库名称,表名与文件名相同
MySQL备份与恢复:
MySQL备份恢复数据的一般步骤
备份一个数据库的例子:
1、备份前读锁定涉及的表
mysql>LOCK TABLES tbl1 READ,tbl1 READ,…
如果,你在mysqldump实用程序中使用--lock-tables选项则不必使用如上SQL语句。
2、导出数据库中表的结构和数据
shell>mysqldump --opt db_name>db_name.sql
3、启用新的更新日志
shell>mysqladmin flush-logs
这样可以记录你备份后的数据改变为恢复数据准备。
4、解除表的读锁
mysql>UNLOCK TABLES;
为了加速上述过程,你可以这样做:
shell> mysqldump --lock-tables --opt db_name>db_name.sql; mysqladmin flush-logs
但是这样可能会有点小问题。上命令在启用新的更新日志前就恢复表的读锁,
在更新繁忙的站点,可能有备份后的更新数据没有记录在新的日志中。
现在恢复上面备份的数据库
1、对涉及的表使用写锁
mysql>LOCK TABLES tbl1 WRITE,tbl1 WRITE,…
2、恢复备份的数据
shell>mysql db_name < db_name.sql
3、恢复更新日志的内容
shell>mysql --one-database db_name < hostname.nnn
假设需要使用的日志名字为hostname.nnn
4、启用新的更新日志
shell>mysqladmin flush-logs
5、解除表的写锁
mysql>UNLOCK TABLES;
希望上面的例子能给你启发,因为备份数据的手法多种多样,你所使用的和上面所述可能大不一样,但是对于备份和恢复中,表的锁定、启用新的更新日志的时机应该是类似的,仔细考虑这个问题。
MySQL数据库优化:
选择InnoDB作为存储引擎
大型产品的数据库对于可靠性和并发性的要求较高,InnoDB作为默认的MySQL存储引擎,相对于MyISAM来说是个更佳的选择。
优化数据库结构
组织数据库的schema、表和字段以降低I/O的开销,将相关项保存在一起,并提前规划,以便随着数据量的增长,性能可以保持较高的水平。
设计数据表应尽量使其占用的空间最小化,表的主键应尽可能短。·对于InnoDB表,主键所在的列在每个辅助索引条目中都是可复制的,因此如果有很多辅助索引,那么一个短的主键可以节省大量空间。
仅创建你需要改进查询性能的索引。索引有助于检索,但是会增加插入和更新操作的执行时间。
InnoDB的ChangeBuffering特性
InnoDB提供了changebuffering的配置,可减少维护辅助索引所需的磁盘I/O。大规模的数据库可能会遇到大量的表操作和大量的I/O,以保证辅助索引保持最新。当相关页面不在缓冲池里面时,InnoDB的changebuffer将会更改缓存到辅助索引条目,从而避免因不能立即从磁盘读取页面而导致耗时的I/O操作。当页面被加载到缓冲池时,缓冲的更改将被合并,更新的页面之后会刷新到磁盘。这样做可提高性能,适用于MySQL5.5及更高版本。
InnoDB页面压缩
InnoDB支持对表进行页面级的压缩。当写入数据页的时候,会有特定的压缩算法对其进行压缩。压缩后的数据会写入磁盘,其打孔机制会释放页面末尾的空块。如果压缩失败,数据会按原样写入。表和索引都会被压缩,因为索引通常是数据库总大小中占比很大的一部分,压缩可以显著节约内存,I/O或处理时间,这样就达到了提高性能和伸缩性的目的。它还可以减少内存和磁盘之间传输的数据量。MySQL5.1及更高版本支持该功能。
注意,页面压缩并不能支持共享表空间中的表。共享表空间包括系统表空间、临时表空间和常规表空间。
使用批量数据导入
在主键上使用已排序的数据源进行批量数据的导入可加快数据插入的过程。否则,可能需要在其他行之间插入行以维护排序,这会导致磁盘I/O变高,进而影响性能,增加页的拆分。关闭自动提交的模式也是有好处的,因为它会为每个插入执行日志刷新到磁盘。在批量插入期间临时转移唯一键和外键检查也可显著降低磁盘I/O。对于新建的表,最好的做法是在批量导入后创建外键/唯一键约束。
一旦你的数据达到稳定的大小,或者增长的表增加了几十或几百兆字节,就应该考虑使用OPTIMIZETABLE语句重新组织表并压缩浪费的空间。对重新组织后的表进行全表扫描所需要的I/O会更少。
优化InnoDB磁盘I/O
增加InnoDB缓冲池大小可以让查询从缓冲池访问而不是通过磁盘I/O访问。通过调整系统变量innodb_flush_method来调整清除缓冲的指标使其达到最佳水平。
MySQL的内存分配
在为MySQL分配足够的内存之前,请考虑不同领域对MySQL的内存需求。要考虑的关键领域是:并发连接——对于大量并发连接,排序和临时表将需要大量内存。在撰写本文时,对于处理3000+并发连接的数据库,16GB到32GB的RAM是足够的。
内存碎片可以消耗大约10%或更多的内存。像innodb_buffer_pool_size、key_buffer_size、query_cache_size等缓存和缓冲区要消耗大约80%的已分配内存。
日常维护
定期检查慢的查询日志并优化查询机制以有效使用缓存来减少磁盘I/O。优化它们,以扫描最少的行数,而不是进行全表扫描。
其他可以帮助DBA检查和分析性能的日志包括:错误日志、常规查询日志、二进制日志、DDL日志(元数据日志)。
定期刷新缓存和缓冲区以降低碎片化。使用OPTIMIZETABLE语句重新组织表并压缩任何可能被浪费的空间。
相关文章
- 详细阅读
- 详细阅读
-
收到无法识别的服务响应数据,可能由详细阅读
未接收到应用服务器响应,网络连接或应用服务器存在异常?宽带的问题,请给宽带客服打电话,让他们来人给您查查。如果是路由器问题,请给品牌路由器客服打电话咨询,她们有在线指导的。
-
如何用函数把多列数据首尾相接成一详细阅读
EXCEL怎么把多列首尾连接放到一列?分享一个碰到这种转置问题时懒得想公式的人想的方法:就是利用数据透视表,但是我也不是wps,不知道和excel的数据透视表有啥区别:首先把你的数据
-
两列比对返回的重复值,如何将重复值详细阅读
Excel中两列数据对比,如何找到相同的并自动填充要查找目标并返回查找区域该目标的值要使用函数VLOOKUP。方法如下:以2007版EXCEL为例,打开下图所示Excel工作表,要在查找范围C列
-
河洛数据可以恢复微信聊天记录吗详细阅读

手机删除的微信记录可以恢复吗?可以的。在平时使用手机的过程中,经常会遇到误删除聊天记录的情况。下面是介绍微信好友删除了聊天记录恢复的方法:1、打开微信,点击上方的搜索按
-
python错把open函数r模式写成了w导详细阅读

python用open打开文件读写,“w”会替换,“a”多次调用函数会重复print语句print [expression ("," expression)* [","]]print >> expression [("," expression)+ [","]][]表示
-
怎么快速找出b列多余的数据详细阅读
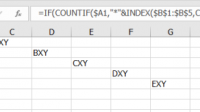
Excel两列数据怎么找出多出来的选择A列,在“条件格式”中,“新建规则”,以“公式”建立规则,输入 =COUNTIF(B:B,A1)=0 格式选择填充色黄色,即可将A列中出现而B列中没有的姓名以黄
-
A2的数据变动,后面对就也要自动变动详细阅读
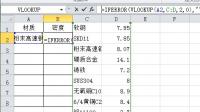
Excel表格中当一列下拉数据改变时,另一列下拉跟着变动怎么设置?假设A2单元格已经设置了数据有效性下拉选择列表,C、D列是材质和密度对应关系,当A2选择材质以后,B2自动填入密度;1、
-
请问一下如何将上面的横向的数据转详细阅读
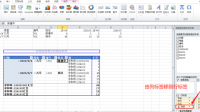
请问在Excel中有啥办法可以将上面的横排数据的格式转化成下面那样,逻辑上的加法关系不变?用数据透视表,日期、楼盘、编号、姓名放行标签、数字字段放数值。列标签自动会添加数
